프로그래머스는 블로그 게재 시 문제 여지가 있어 자세한 내용 없이 문제 제목과 링크로 대체합니다.
대괄호, 중괄호, 소괄호로 구성된 문자열이 주어질 때 이 문자열을 왼쪽으로 한 칸씩 옮기면서(회전하면서) 올바른 괄호 문자열이 만들어지는 횟수를 찾는 문제였다.
( ) { } [ ] , ( { } ) [ ] 와 같이 괄호들이 순서대로 잘 닫겨 있다면 올바른 괄호 문자열이다.
옮긴 칸수
문자열
올바른지 여부
0
( ) { } [ ]
네
1
) { } [ ] (
아니오
2
{ } [ ] ( )
네
3
} [ ] ( ) {
아니오
4
[ ] ( ) { }
네
5
] ( ) { } [
아니오
올바른지 여부에 "네"가 총 3개니까 결과값으로 3을 리턴하면 되는 형태
1) 문자열을 왼쪽으로 하나씩 미는 반복문이 필요하고
2) 문자열 내부를 돌면서 올바른지 여부를 확인하는 반복문도 필요했다 반복문 내부에는 스위치문과 스택을 활용해 2-1) 열린 괄호들이면 push하고 2-2) 닫힌 괄호들이면, 스택이 비지 않았다는 전제 하에 - pop한 열린 괄호가 지금 괄호와 짝인 경우에만 올바른 문자열인지 판단하는 r 값을 true로 바꿔주기로
1) 스택이 비어 있고 r 값이 true라면 올바른 문자열이니까 answer의 값을 하나 올려준다 1) 마지막으로 문자열을 왼쪽으로 미는 로직을 추가했다
코드로 보면 이런 느낌이에요. 중복도 있고 조금 더 예쁘게 짤 수 있을 것 같기는 한데 일단 풀었다에 의의를 두는 코드라죠^^
import java.util.*;
class Solution {
public int solution(String s) {
int answer = 0;
String sc = s;
int size = sc.length();
for (int i=0; i<size; i++){ // 문자열을 왼쪽으로 미는 반복문
// System.out.println("현재 문자열은 "+sc);
boolean r = false;
Stack<Character> stack = new Stack<>();
// 문자열 내부를 검사하는 반복문
for (int j=0; j<size; j++){
char c = sc.charAt(j);
switch (c){
case '(':
stack.push(c); break;
case '{':
stack.push(c); break;
case '[':
stack.push(c); break;
case ')':
if (stack.isEmpty() == false && stack.pop() == '(') {
r = true;}
else { r = false;} break;
case '}':
if (stack.isEmpty() == false && stack.pop() == '{') {
r = true; }
else { r = false; } break;
case ']':
if (stack.isEmpty() == false && stack.pop() == '[') {
r = true; }
else { r = false; } break;
}
// System.out.println(j + "번 자리에서 " + r);
}
if (stack.isEmpty() == true && r == true) {
// 스택이 비어있고 true 라면 해당 회차는 올바름
answer++;
// System.out.println(i+"칸 움직인 후에 " + answer);
}
if (1<size){
String temp = sc.substring(1);
char back = sc.charAt(0);
sc = temp + String.valueOf(back);
}
}
return answer;
}
}
중간중간 결과물이 어떻게 나올지 궁금해서 온라인 컴파일러를 활용해 출력해봤다. 하다보니 스위치문에서 브레이크/컨티뉴가 헷갈렸거든요 (사실 아직도임 ㅋ)
내 의도대로 올바른 회차에만 answer 변수를 카운트하는 모습까지 확인된다.
정답 코드도 공부하자면
내가 스위치문으로 구성한 올바른 코드 확인 로직을 해쉬맵으로 구현했다.
HashMap<Character, Character> map = new = HashMap<>();
map.put(')', '(');
그리고 문자열을 왼쪽으로 미는 대신에 문자열 2개를 이어 붙이고 시작 인덱스를 하나씩 뒤로 보내는 방법을 택했다. ( ) { } [ ] ( ) { } [ ]
해시맵 안에 인덱스에 해당하는 모양이 없다면 열리는 괄호라는 의미라 스택에 집어 넣는다.
모양이 있고 스택이 비어 있지 않다면 스택에서 꺼낸 결과와 해시맵을 비교해서 짝이 맞지 않으면 다음 문자열을 확인하러 보낸다
위에서 중단하고 넘어가지 않았고 스택도 비어 있다면 올바른 괄호 문자열이다.
처음에는 막막했는데 책 기준 10번 문제 정도 오니까 시간이 조금 오래 걸리고 내 로직이 정답과는 많이 다르긴 해도 하나씩 풀 수는 있다 소소하게 작은 것부터 이뤄나가기👊
오늘의 문제는 "코딩 테스트 합격자 되기:자바 편"에 있는 10진수를 2진수로 변환하기 이다. 저자가 직접 출제한 문제라 프로그래머스 같은 곳에 돌려서 결과 확인이 어렵더라. 프로그래머스 아닌 문제도 있었으면 좋겠다 하긴 했는데 이 점은 좀 아쉬움... 하지만 자료구조별로 잘 정리되어 있고 문제마다 분석하는 방법과 푸는 흐름을 잘 설명해 줘서 코테 입문자에게는 따라서 공부하기가 좋다. 추천합니다!
그럼 문제부터 보겠습니다. 10진수를 입력받아 2진수로 변환하는 함수를 구현하라는 문제입니다. 10진수를 2진수로 변환하는 법은 간단하죠 2로 나눠서 남은 나머지들을 뒤에서부터 적으면 된다죠
출처 : 도서 149p
일단 내가 푼 코드는 이렇다.
import java.util.*;
import java.lang.*;
import java.io.*;
// The main method must be in a class named "Main".
class Main {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
int v = 27;
while( v > 0 ){
stack.push(v%2);
v = v/2;
}
while(!stack.isEmpty()){
System.out.print(stack.pop());
}
}
}
파트 1: 이제는 모두의 AI 리터러시 파트 2: 누구나 쉽게 이해하는 인공지능 기술 파트 3: AI 리터러시 업그레이드 생성형 AI 서비스 가이드 파트 4: '나' 맞춤 AI 리터러시
이렇게 구성되어 있는데 순서대로 어떤 내용들이 들어 있는지 정리해 볼게요 아래에 이어지는 내용은 책을 보면서 정리한 것임을 미리 밝혀둡니다 (아주 간혹 내 생각이나 추가 공부한 내용 포함될지도)
파트 1: 이제는 모두의 AI 리터러시
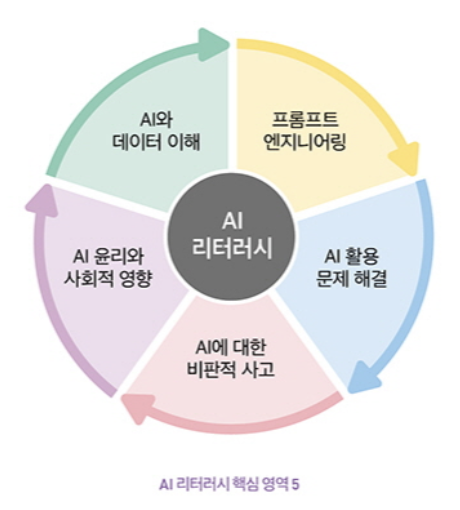
AI 리터러시는 “AI 기술을 이해하고, 활용하며, 비판적으로 평가할 수 있는 종합적인 능력”을 의미한다.
- AI 리터러시의 핵심 영역 5가지 1) AI 데이터의 이해 : AI 기본 원리와 작동 방식을 이해하고, AI의 기반인 데이터의 중요성을 인식하며 이를 해석/활용하는 능력 2) 프롬프트 엔지니어링 : AI에게 효과적인 명령어/질문을 제시하여 원하는 결과를 얻어내는 능력 3) AI 활용 문제 해결 : 일상생활과 업무 환경에서의 다양한 문제를 AI 기술을 활용하여 해결하는 능력 4) AI에 대한 비판적 사고 : AI의 한계와 잠재적 편향성을 인식하고, 생성된 결과물을 비판적으로 평가하는 능력 5) AI 윤리와 사회적 영향 : AI 사용에 따른 윤리적 문제와 사회적 영향을 인식하고, 관련 법규와 정책을 이해하는 능력
출처 : 도서 18페이지
프롬프트 엔지니어링은 “AI에게 효과적으로 지시를 내리고 원하는 결과를 얻어내는 기술”이다. 프롬프트에도 어느 정도 공식이 존재하며, 그에 맞게 작성해야 원하는 결과물을 뽑아낼 수 있는 확률이 높아진다. 한두 줄의 너무 짧은 프롬프트 입력으로는 절대 좋은 결과물을 얻을 수 없다.
- 프롬프트 구성시 꼭 포함되어야 하는 필수 요소 3가지 1) 지시사항(Instruction) : AI에게 무엇을 해야 하는지 구체적으로 알려주는 명령 2) 맥락(Context) : AI가 작업을 수행하는데 필요한 배경 정보를 제공 3) 출력형식(Output Format) : AI에게 원하는 출력 형식을 알려주는 지시어
- AI 답변의 품질을 높이는 보조 프롬프트 요소 1) 입력 데이터(Input Data) : AI가 작업을 수행하는 데 필요한 데이터 LIKE 요약할 글, 번역할 문장, 참고해야 할 최신 정보 등 2) 제약조건(Constraints) : AI의 답변에 제한을 두어, 더 구체적이고 집중된 결과를 도출하게 함 3) 예시(Example) : AI에게 어떤 답변을 원하는지 구체적으로 알려줌
구성요소
예시
지시사항
ㅇㅇ에 관한 에세이를 써주세요. ㅇㅇ에 대한 토론 주제를 제시해주세요.
맥락
이번 보고서는 ~~에 대한 것으로, 핵심요소는 ~~다. 이 스크립트는 ~~에서 발표될 예정이며, ~~가 주된 내용이다.
출력형식
표 형식으로 정리해주세요. 최근의 사건이 가장 위로 오는 타임라인 형식으로 제시해주세요.
입력 데이터
다음 데이터를 바탕으로 분석 보고서를 작성해주세요(+데이터 파일) 다음 문장을 한국어에서 스페인어로 번역해주세요(+한글 문장)
제약조건
500자 이내로 요약해주세요. 00연도 이후의 자료로만 구성해주세요.
예시
보고서 개요, 레시피, 여행 계획, 그림 등 가능한 한 구체적이고 명확하게 제공
그 외에도 사용되는 프롬프트 엔지니어링 기법들로,
1) 제로샷 프롬프팅 : AI에게 별도 예시를 주지 않은 상태에서 새로운 작업을 하도록 요청. AI가 기존에 학습한 내용을 바탕으로 처음 접하는 작업/질문에 대응하게 함. 전문적인 작업에서는 정확도가 떨어질 수 있으며, AI의 학습 범위를 벗어나는 주제에는 관련 없는 답변을 생성할 수도 있다는 한계 존재 2) 원샷 프롬프팅 : AI에게 딱 1개의 예시만 제공하여 작업을 지시. 최소한의 정보로 최대한의 결과를 얻고자 할 때 사용함. 대표성이 높은 예시를 제공해야 원하는 결과를 얻을 확률이 높아짐 3) 퓨샷 프롬프팅 : AI에게 여러 개의 예시를 제공하여 작업을 지시. 원하는 결과물의 스타일/특징과 가까운 결과를 낼 확률이 높으나, 제공된 예시 간 일관성이 없거나 너무 많은 경우 역효과가 날 수도 있음 4) CoT 프롬프팅(Chain of Thought) : AI에게 문제 해결 과정을 단계별로 설명하도록 유도 5) 역할 할당 프롬프팅 : AI에게 특정 역할이나 관점을 부여하여, 그 역할에 맞는 방식으로 응답을 생성하도록 유도
주의해야 할 문제들로는1) AI의 환각현상(할루시네이션 Hallucination)은 AI가 실제로 존재하지 않는 정보를 마치 사실인 것처럼 제시하는 현상을 의미. AI가 학습한 데이터를 바탕으로 가장 확률적으로 높은 답변을 생성하는 과정에서, 실제로 존재하지 않는 정보나 잘못된 정보를 사실처럼 제시하는 것. 불완전한 데이터, 생성 방식의 특성, 명확하지 않은 프롬프트 등으로 인해 발생하게 됨. 방지를 위해 팩트 체크를 꼭 해야 함. 다른 플랫폼 등을 활용해 AI 답변의 사실 관계를 확인해야 함
2) AI의 편향성이 있음. AI가 학습하는 데이터들 속에는 이미 세상에 존재하는 수많은 편견들이 반영되어 있음. AI가 이 데이터들을 그대로 학습하면서 편향될 수 있음. 그렇기에 AI의 답변을 무조건 믿기보다는 비판적으로 바라볼 줄 알아야 함.
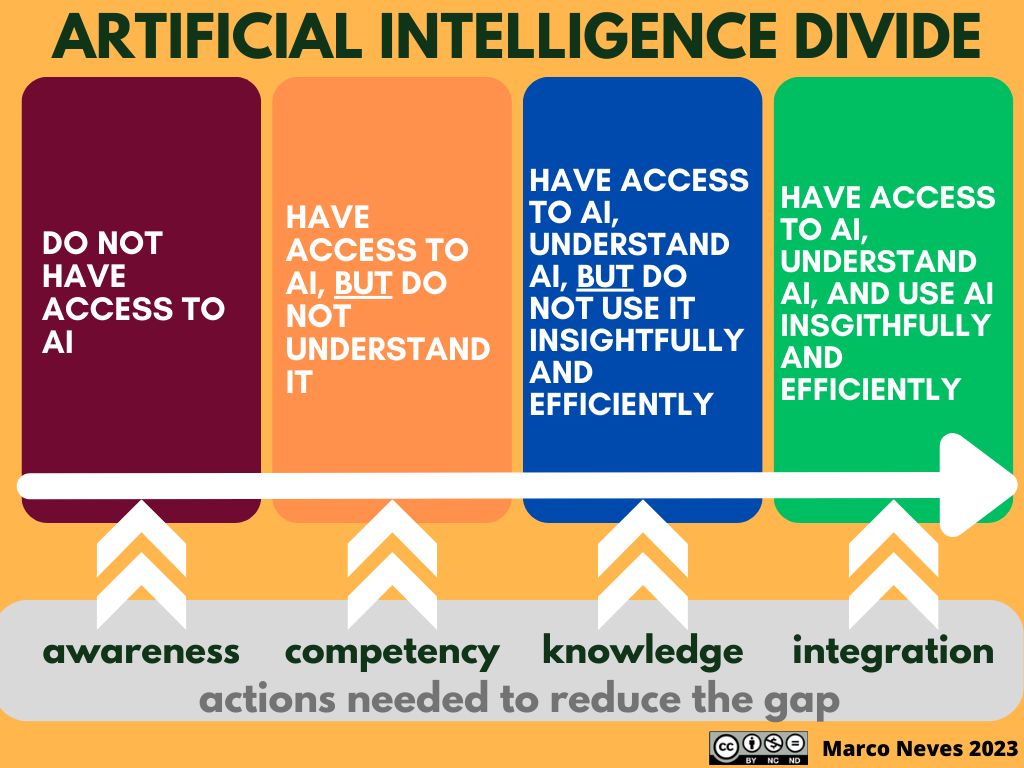
AI 디바이드란 “AI를 효과적으로 사용할 수 있는 사람과 그렇지 못한 사람 간의 격차”를 의미함. AI 교육 전문가 마르코 누베즈에 따르면, AI 디바이드에는 총 4개 수준이 존재
1) 레벨 1 인식 : AI 접근 불가 2) 레벨 2 사용 : AI 접근 가능하나, AI에 대한 이해는 없음 3) 레벨 3 숙지 : AI에 접근하고 이해하지만, 통찰력 있고 효율적인 사용은 못함 4) 레벨 4 통합 : AI에 접근하고 이해하며, 통찰력 있고 효율적인 사용 가능함
출처 : 마르코 누베즈 링크드인 포스트
나는 아주 좋게 봐줘야 레벨 2에 속하는 것 같다. 왜냐 얼마 전에 블로그 쓰면서 챗지피티한테 이미지 만들어달라 했는데 이 난리였거든요ㅋ 그래서 빠르게 포기했는데요. 이번에 이 책 자세히 읽으면서 나에게는 프롬프트 엔지니어링 스킬이라는 게 전혀 없다는 사실을 뼈저리게 느꼈다. 예시도 줬는데... 지피티 이 자식... 했는데 잘못은 나에게 있었던 걸로 ㅋㅎ 반성하자 진짜
파트 2: 누구나 쉽게 이해하는 인공지능 기술
여기서는 우리가 실제로 사용하고 있는 서비스들 속에 숨어 있는 AI를 설명해 줘요. 넷플릭스와 유튜브의 추천 알고리즘 속에 녹아 있는 콘텐츠 기반/협업 필터링이라거나, 시리와 같은 AI 비서 속에 숨어 있는 음성 인식, 자연어 처리, 대화 관리, 음성 합성과 같은 기술들입니다. 그리고 AI의 개념과 역사, 주요 적용 분야에 대해 설명하고 있어서 유용해요. 꼭 책을 읽으면서 내용 파악해 보시기를 추천해요. 그리고 조금 더 자세한 내용이 궁금하다면 아까 소개한 "비전공자도 이해할 수 있는 AI 지식"으로 넘어가면 좋을 것 같아요.
이 부분을 읽으면서 이외에도 내 일상에 스며든 AI 기반 서비스들이 뭐가 있을지 고민해 봤는데 유튜브, 넷플릭스, 애플뮤직, 밀리의 서재, 왓챠피디아 같은 서비스들은 다 추천 알고리즘을 기반으로 나를 조종하고 있고, 요즘은 듀오링고와 플랭 같은 AI 기반 언어 공부 앱들로 공부도 하고 있다. 일할 때는 클로바노트로 회의록 쓸 때 도움도 받고 하니까 노션으로 프로젝트 정리도 하고, 내 개인적인 기록도 남기기도 한다. 이렇게 보니 진짜 내 생활의 전부라고 말해도 될 정도다. 이렇게나 AI 속에서 살고 있지만 정작 생성형 AI와는 전혀 친하지가 않은데요. 그래서 이어질 파트에서 깊게 공부해 보겠습니다.
파트 3: AI 리터러시 업그레이드 생성형 AI 서비스 가이드
이번 파트에서는 결과물 종류나 활용 목적에 따라 AI 서비스들을 다섯 가지로 나눈 후 각 서비스들의 개요, 특별한 기능, 간단한 활용법에 대해 소개한다. [대화형, 이미지 생성형, 동영상 생성형, 특화 기능 생성형, 연구 및 교육용] 여기서부터는 내가 이용해 볼 만한 것들만 추렸다. 자세한 건 책을 직접 찾아보길 추천한다.
[대화형 AI]
인간과 자연스럽게 대화를 나눌 수 있는 인공지능으로 사용자가 입력하는 텍스트에 적절하게 응답하거나 정보를 제공하는 기술이다. 앞서 파트 2장에서 소개한 대규모 언어 모델(LLM)을 기반으로 동작한다.
(1) 챗GPT, ChatGPT, https://chatgpt.com/ - 기본적인 문서 작성부터 정보 검색, 이미지와 파일 분석, DALL-E 모델 기반 고품질 그림 생성 - GPT 모델에 기반한 애드온을 찾을 수 있는 GPT 스토어라는 기능 존재
(2) 클로드, Claude, https://claude.ai/ - 자연스러운 느낌의 글쓰기 제공. 일반적인 질문-답변부터 문서/이미지 분석 - 생성된 결과물을 실시간 편집할 수 있는 작업 공간인 아티팩트 기능을 통해 코드 실행, 그래프 생성, 동적 이미지 제작, 게임 개발까지 가능 - 인터넷에 연결되어 있지 않아 최신 정보를 실시간으로 제공받을 수는 없음
(3) 제미나이, Gemini, https://gemini.google.com/ - 질문 답변, 이미지 및 문서 분석 등 대화형 AI 기본 기능 제공 - 구글 서비스와 호환. 구글 드라이브/지메일 검색 및 정리, 구글 독스 활용 문서 작성 등. 이마젠3 모델 기반 고품질 이미지 생성 - 인터넷 검색을 통한 최신 정보 제공. GPT 스토어와 유사한 Gem이라는 기능 존재
출처 각 서비스 홈페이지
(4) 클로바X, ClovaX, https://clova-x.naver.com/ - 하이퍼클로바X 모델을 기반으로 하여 타 서비스에 비해 한국어/한국 데이터에 특화 - 스킬 기능을 통해 네이버 서비스들과 호환, 에이전트 기능을 통해 전문적인 작업 지원
(5) 노트북LM, NotebookLM, https://notebooklm.google - 여러 문서를 비교 분석하거나 여러 문서에서 정보를 바로바로 찾아야 할 때 유용 - 문서 형식 자유. 구글 문서/슬라이드, PDF, 텍스트, URL 모두 분석 가능 - 제미나이 1.5 프로 기반 이미지/차트/도형 분석, 출처 인용, 자료 요약 또는 새 목차 작성 등
출처 각 서비스 홈페이지
(6) 퍼플렉시티, Perplexity, https://www.perplexity.ai - 실시간 웹 검색을 통한 최신 정보 제공과 신뢰할 수 있는 출처 제시로 AI의 환각현상 최소화 - 작성한 문서를 업로드하고 역으로 참고 문헌을 찾아달라고 요청할 수도 있음
(7) 웍스AI, Wrks AI, https://wrks.ai/ko - 대화형 AI부터 문서 번역, 데이터 분석, 회의록 작성 등 직장인 맞춤형 기능 제공 - 나만의 비서 만들기 기능을 통해 회사 규정을 학습시키거나, 반복 업무를 자동화하는 등 커스텀 가능
[이미지 생성형 AI]
텍스트를 입력받아 원하는 이미지를 만들어주는 인공지능 기술이다. 대규모 이미지 데이터로 학습된 인공지능 모델을 기반으로 작동한다.
한빛미디어의 혼자 공부하는 시리즈 중에서 자기가 공부하고 싶은 걸 1권 선택해서 매주 커리큘럼 따라 공부하고 숙제 및 정리 글을 올리면 되는데요.
내가 13기에 신청한 건 "혼자 공부하는 네트워크"
출처 : 한빛미디어 공식 사이트
혼공학습단의 족장(?)님이 내주시는 숙제 커리큘럼은 아래와 같아요.
출처 : 혼공학습단 홈페이지
본격적으로 숙제를 하기 전에! 이번 주가 혼공단의 첫 번째 주니까 앞으로 6주간 공부할 책에 대해서도 잠시 살펴볼게요
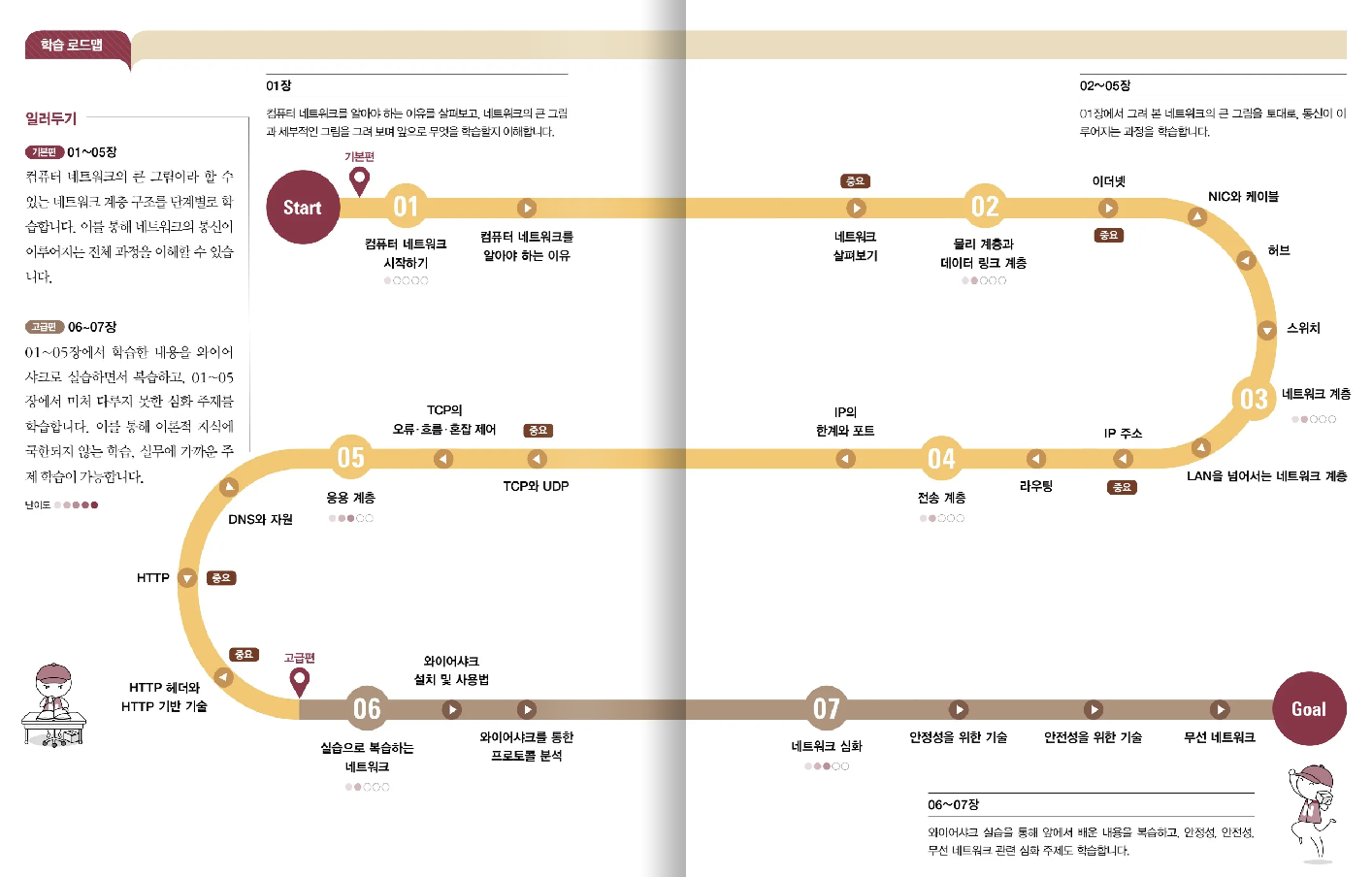
책을 펼치면 가장 먼저 "학습 로드맵"이 나와요. 목차보다 먼저 나와서, 이 책을 통해 무엇을 배우게 될지 대략적으로 파악할 수 있어요. 게다가 책을 100% 활용하기 위한 여러 팁도 있는데요. 1. 핵심 개념과 용어를 따로 정리한 PDF 파일인혼공 용어 노트 2. 혼자 이해 하기가 어렵다면 들을 수 있는무료 강의 3. 심화 학습에 필요한 파일들을 보고 저자에게 직접 질문도 할 수 있는 깃헙 마지막으로 4. 의지박약자를 강제로 공부하게 하는혼공학습단
출처 : 한빛 미디어 공식 사이트 > 미리보기 기능
목차는 대제목만 살펴볼게요. 우리 혼공단 커리큘럼과 순서가 같아요. 매주 해당하는 내용에만 하이라이트를 쳐볼게요
<목차> Chapter 1. 컴퓨터 네트워크 시작하기 Chapter 2. 물리 계층과 데이터 링크 계층 Chapter 3. 네트워크 계층 Chapter 4. 전송 계층 Chapter 5. 응용 계층 Chapter 6. 실습으로 복습하는 네트워크 Chapter 7. 네트워크 심화
그럼 1주차 공부를 시작해 볼까요
# 컴퓨터 네트워크란 여러 장치가 연결되어 정보를 주고받을 수 있는 통신망을 의미 많은 프로그램이 네트워크를 통해 다른 장치와 상호작용하며 실행됨 >> 프로그램을 개발하거나 유지보수 할 때 네트워크 배경지식을 활용해야 하는 경우가 많기에 공부가 필요
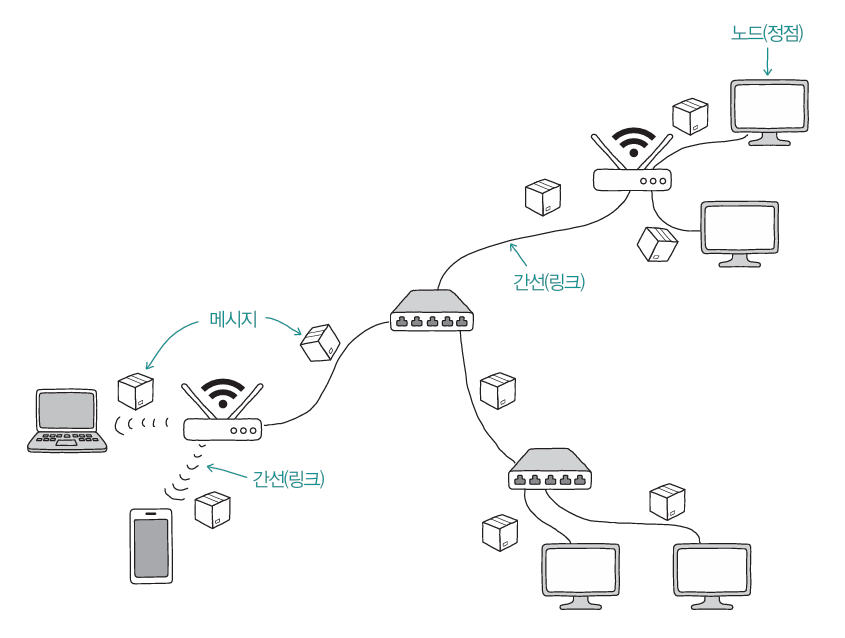
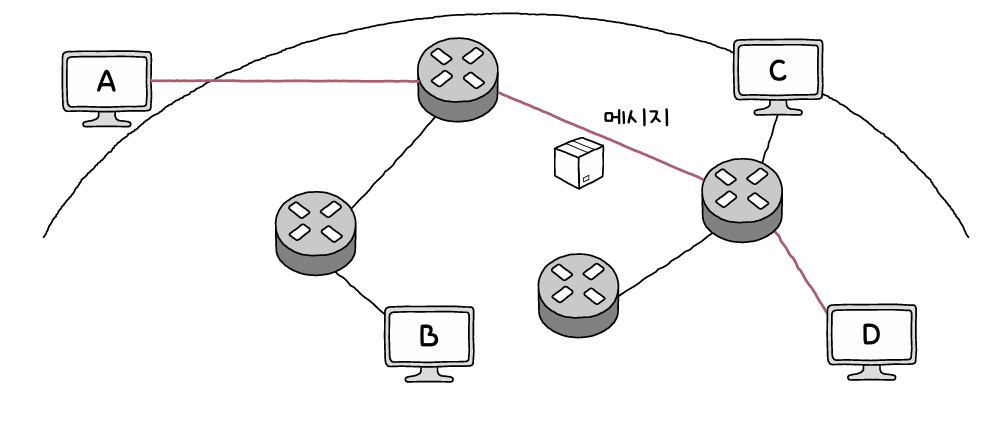
# 네트워크의 기본 구조 모든 네트워크는 노드, 노드를 연결하는 간선, 노드 간 주고받는 메시지로 구성됨 노드 : 정보를 주고받을 수 있는 장치. 호스트, 서버, 네트워크 장비 등이 존재 간선 : 정보를 주고 받을 수 있는 유무선의 통신 매체 메시지 : 통신 매체로 연결된 노드가 주고받는 정보. 웹 페이지, 파일, 메일 등 다양
출처 : 한빛출판네트워크 홈페이지 > 채널.H
# 범위에 따른 네트워크 분류 LAN(Local Area Network) : 가까운 지역을 연결한 근거리 통신망. 가정, 학교, 기업과 같이 한정된 공간의 네트워크 WAN(Wide Area Network) : 먼 지역을 연결하는 광역 통신망. 멀리 떨어진 LAN을 연결할 수 있는 네트워크로, ISP(Internet Service Provider)라는 인터넷 서비스 업체가 구축하고 관리. 국내에 대표적인 ISP는 3대 통신사가 있음.
더 세밀하게 나누면 LAN과 WAN 사이에 2개의 개념이 더 존재. 순서를 따지자면, (넓음) WAN >> MAN >> CAN >> LAN (좁음) - MAN은 도시나 대도시 단위로 연결되는 규모의 네트워크를 의미 - CAN은 학교/회사의 여러 건물 단위로 연결되는 규모의 네트워크를 의미
# 메시지 교환 방식에 따른 네트워크 분류 회선 교환 방식 : 메시지 전송로인 회선(Circuit)을 먼저 설정하고 이를 통해 메시지를 주고받는 방식. 요즘은 안 쓰이지만 전통적인 전화망과 같은 형태. 주어진 시간 동안 전송되는 정보의 양이 비교적 일정하다는 장점이 있으나, 반대로 회선의 이용 효율이 낮아질 수 있다는 단점도 존재. 하단의 왼쪽 그림 내 붉은 선처럼 회선을 먼저 설정해야 이 경로를 통해 메시지가 오갈 수 있음
출처 : 혼공학습단 홈페이지 > 읽을거리
패킷 교환 방식 : 메시지를 패킷(Packet)이라는 작은 단위로 쪼개어 전송. 회선 교환 방식에 비해 네트워크 이용 효율이 상대적으로 높음. 상단의 오른쪽 그림처럼 패킷들이 회선을 타고 필요한 곳으로 이동하게 됨. 패킷은 헤더, 페이로드, 트레일러로 구성. 패킷이 택배와 비슷한 개념이라, 헤더(Header)는 어디로 가야 할지 적힌 택배 송장 같은 개념이고, 페이로드(Payload)는 전송하고자 하는 데이터가 담겨 있는 택배 안의 내용물, 트레일러(Trailer)는 부가적인 정보를 표시한 것.
출처 : 혼공학습단 홈페이지 > 읽을거리
# 주소/송수신지 유형에 따른 전송방식 유니캐스트(Unicast) : 하나의 수신지에 메시지를 전송하는 방식. 1:1 전송 방식 브로드캐스트(Broadcast) : 자신을 제외한 네트워크상의 모든 호스트에게 전송하는 방식 멀티캐스트(Multicast) : 네트워크 내의 동일 그룹에 속한 호스트에게만 전송하는 방식 애니캐스트(Anycast) : 네트워크 내 동일 그룹에 속한 호스트 중 가장 가까운 호스트에게만 전송하는 방식
# 프로토콜(Protocol)이란 노드 간에 정보를 올바르게 주고받기 위해 합의된 규칙이나 방법. 서로 다른 장치들이 정보를 제대로 주고받으려면 필요. IP, HTTP, TCP, ARP 등 프로토콜별로 목적과 특징이 모두 다름
# 네트워크 참조 모델이란 네트워크를 통해 정보를 주고받을 때 정형화된 여러 단계를 거치는데, 이를 계층으로 나눈 구조를 의미. 계층을 나누는 이유는, 1) 네트워크 구성과 설계가 용이해지기 때문 : 각 계층의 역할이 정해져 있어 그에 맞게 프로토콜과 네트워크 장비를 구성 가능 2) 네트워크 문제 진단과 해결에 용이 : 문제가 발생 시 계층별로 진단하면서 문제 발생 지점을 쉽게 추측하고 해결 가능
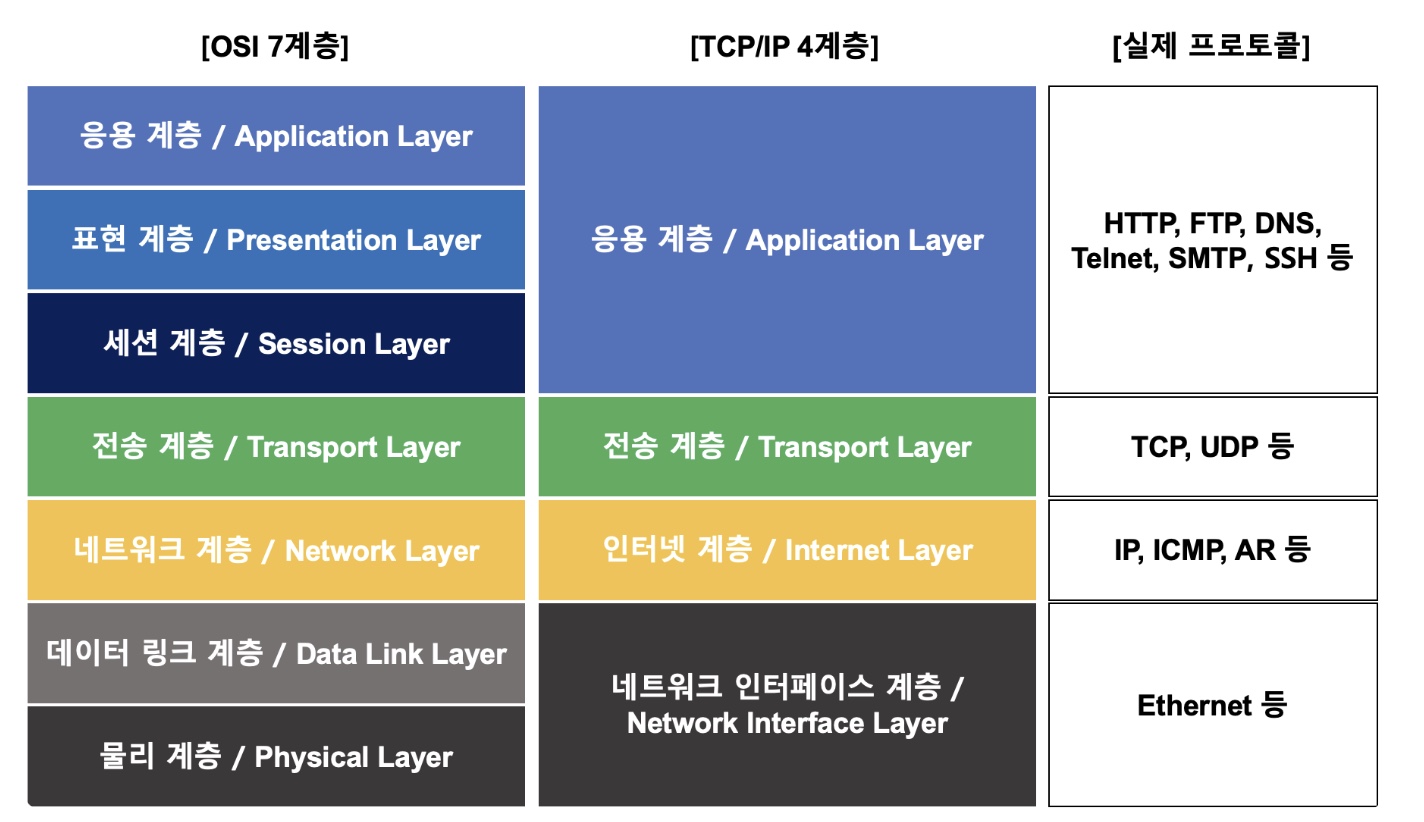
네트워크 참조 모델은 크게 OSI 모델과 TCP/IP 모델로 나눠짐
여기부터는 심화 공부를 위해 다른 책과 블로그도 참고하며 정리했는데 비슷한/중복되는 개념도 그냥 적었습니다. 사담인데 모 기업에서 계층별로 프로토콜 구분하랬는데 공부 안 해서 틀렸거든요^ㅁ^ 아무래도 대학 졸업장 반납해야 할 수준... 그래서 좀 힘줘서 자세히 공부해봤음다 하지만 프로토콜별로는 나중에 따로 정리할게요... 암튼 공부 킵고잉
# OSI 7계층 (낮은 >> 높은 순으로)
(1) 물리 계층 Physical Layer - OSI 모델 최하단에 있는 계층 - 0과 1로 표현되는 비트 신호를 주고받음 - 주로 전기/기계/기능적 특성을 이용해 통신 케이블로 데이터를 전송하는 물리적인 장비 전송에 필요한, 두 장치 간의 실제 접속과 전달 등 기계/전기/기능/절차적 특성에 대한 규칙을 정의 - 전송 단위(프로토콜 데이터 단위, PDU)는 비트 Bit - 장비는 통신 케이블, 리피터, 허브(반이중) 등 - 관련 프로토콜로는 RS-232C, X.21 등
(2) 데이터 링크 계층 Data Link Layer >> 흐름/오류/순서 제어 - 네트워크 내 주변 장치 간의 정보를 올바르게 주고받기 위한 계층 - 물리 계층을 통해 주고받는 정보에 오류가 없는지 확인 - MAC 주소 체계를 통해 네트워크 내 송수신지를 특정 - 전송 과정에서 발생할 수 있는 충돌 문제를 해결하는 계층 - 물리적으로 연결된 인접한 개방 시스템들 간 신뢰성 있고 효율적인 정보 전송을 위해 시스템 간 연결 설정과 유지 및 종료를 담당 - 물리 계층을 통해 송수신되는 정보의 오류의 검출과 회복을 위한 오류제어와, 송수신 측 속도 차이를 해결하기 위해 흐름을 관리는 흐름 제어, 프레임의 순서적 전송을 위한 순서 제어(재전송) - 전송 단위인 프레임(frame)에 물리적 주소(MAC 주소)를 부여 - 장비는 랜카드, 브리지, 스위치(전이중), 이더넷 등 - 관련 프로토콜로는 HDLC, LAPB, LLC, MAC, LAPD, PPP 등
(3) 네트워크 계층 Network Layer - 메시지를 다른 네트워크에 속한 수신지까지 전달하는 계층 - 네트워크 간 통신을 통해 인터넷을 가능하게 하는 계층 - IP 주소를 통해 통신하고자 하는 수신지 호스트와 네트워크를 식별하고, 원하는 수신지에 도달하기 위한 최적의 경로 결정(라우팅) - 개방 시스템들 간 네트워크 연결을 설정/유지/해제하는 관리 기능과 데이터의 교환/중계 기능, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행 - 라우터를 통해 경로를 선택하고 주소를 정하고(IP), 경로에 따라 패킷을 전달 = 발신지/목적지의 논리 주소가 추가된 패킷을 최종 목적지까지 전달 (IP 헤더 붙음) - 전송 단위는 패킷 - 장비는 라우터 - 관련 프로토콜로는 IP, ICMP, IGMP, ARP, RARP, X.25 등
(참고) IP의 특징 - 신뢰성(에러 제어) / 흐름 제어 기능 없음 - 비연결성 / 비신뢰성 - 인터넷 주소 지정과 라우팅 - 패킷 단편화와 재조립 - 데이터그램 기반, 패킷 전송
(4) 전송 계층 Transport Layer - 신뢰성 있고 안정성 있는 전송을 해야 할 때 필요한 계층 - OSI 7계층 중 하위 3계층과 상위 3계층의 인터페이스 담당 - 패킷의 흐름을 제어하거나 전송 오류를 점검해 신뢰성 있고 안정적인 전송이 이루어지도록 함 (패킷이 정상적으로 보내졌는지, 중간에 유실은 없었는지, 순서가 뒤바뀌지는 않았는지 확인) - 논리적 안정과 균일한 데이터 전송 서비스를 제공해 종단 시스템 간(end to end) 투명한 데이터 전송 지원 - 종단 시스템 간(단말기 사이에) 전송 연결 설정, 데이터 전송, 연결 해제 기능 - 주소 설정, 다중화(분할 및 재조립), 오류 제어, 흐름 제어 - 두 지점 간 신뢰성 있는 데이터 송수신을 지원하는 역할, 신호를 분산하고 다시 합치는 과정을 통해 에러와 경로를 제어 - 전송 단위는 세그먼트 - 장비는 게이트웨이 - 관련 프로토콜로는 TCP, UDP TCP는 신뢰성, 연결지향적인 프로토콜. 패킷의 전송. 오류/혼잡/흐름 제어 UDP는 비신뢰성, 비연결성, 실시간성을 가진 프로토콜
(5) 세션 계층 Session Layer - 통신을 주고받는 호스트의 응용 프로그램 간 연결 상태인 "세션"을 관리하는 계층 - 송수신 측 간의 관련성 유지, 대화제어 담당 - 대화(회화) 구성 및 동기 제어, 데이터 교환 관리 기능 - 송수신측간의 데이터 전송, 연결 해제, 동기 처리 등의 대화를 관리하기 위해 토큰 사용 - 송수신측간의 대화 동기를 위해 전송하는 정보의 일정한 부분에 체크점을 두어 정보의 수신 상태를 체크함 (체크점=동기점) - 동기점은 오류가 있는 데이터 회복을 위해 사용하는 것 소동기점 : 하나의 대화 내, 수신 측으로부터 확인 신호 ACK 안 받음 대동기점 : 전송하는 데이터의 처음/끝, 확인 신호 받음 - API. Socket. TCP/IP 세션 체결. 포트 port 번호 기반 통신 세션
(6) 표현 계층 Presentation Layer - 서로 다른 표현 형태를 갖는 시스템 간 상호 접속을 위해 필요한 계층 like 번역가 - 코드 변환(사람 언어인 문자를 컴퓨터가 이해 가능한 코드로 변환) - 데이터 암호화, 데이터 압축, 구문 검색, 정보 형식(포맷) 변환, 문맥 관리 기능
(7) 응용 계층 Application Layer - OSI 참조 모델 최상단에 있는 계층 - 사용자&사용자가 이용하는 응용 프로그램과 가장 밀접한 계층 - 사용자(응용 프로그램)이 OSI 환경에 접근할 수 있도록 서비스 제공 - HTTP(80), FTP(21), SMTP(25), SNMP, POP3, IMAP, Telnet(23), DNS(53) * 세션부터 응용까지 전송 단위는 메시지
정리하자면 아래 그림의 OSI 7계층과 같답니다. 네트워크를 이론적으로 기술하고 이해할 때 사용하는 "이상적 설계" 같은 거래요. 그럼 계속해서 오른쪽의 TCP/IP 모델도 볼까요? 구현에 중점을 두어 실제 사용하기 위한 "실용적 구현" 같은 거라고 하네요. 이런 차이점이 있다는 건 처음 알았다.
(1) 네트워크 액세스/인터페이스 계층 Network Access/Interface Layer - OSI 모델에서의 물리와 데이터 링크 계층과 유사(간혹 데이터 링크 only로 다르게 보는 시선도 있긴 함) - 실제 데이터(프레임)을 송수신하는 역할 - 에러 검출, 패킷의 프레임화 - 네트워크 접근 방법, 프레임 포맷, 매체에 독립적으로 동작하도록 설계 - 물리적인 주소로 MAC 사용 - LAN, 패킷망 등에 사용됨 - 이더넷, IEEE 802, HDLC, X.25, RS-232C, ARQ 등
(2) 인터넷 계층 Internet Layer - OSI 모델에서의 네트워크 계층과 유사 - 데이터 전송을 위한 주소 지정(어드레싱), 경로 설정(라우팅), 패키징 기능 제공 - 네트워크 상 최종 목적지까지 정확하게 연결되도록 연결성 제공 - IP, ICMP, IGMP, ARP, RARP
(3) 전송 계층 Transport Layer - OSI 모델에서의 전송 계층과 유사 - IP와 Port를 이용하여 프로세스와 통신 - 호스트들 간의 신뢰성 있는 통신 제공 - 통신 노드 간 연결 제어 - TCP, UDP, RTCP
(4) 응용 계층 Application Layer - OSI 모델에서의 세션, 표현, 응용 계층을 합친 것과 유사 - 응용 프로그램 간 데이터 송수신 제공, 프로토콜 정의 - 다른 계층 서비스에 접근할 수 있게 하는 애플리케이션 제공 - HTTP(80), HTTPS, FTP(21), SMTP(25), SNMP, POP3, IMAP, Telnet(23), DNS(53)
책에서는 각 계층을 추후에 자세히 학습할 예정이라고 했다. 나중에 해당 챕터에서 공부하면서 비교하고 조금 더 압축적으로 요약해보고자 한다.
#캡슐화와 역캡슐화 패킷은 송신 과정에서 캡슐화가, 수신 과정에서 역캡슐화가 이루어짐. 네트워크 참조 모델도 마찬가지 정보 전송 시 각 계층에서는 상위 계층으로부터 받은 패킷을 페이로드 삼아, 프로토콜에 걸맞은 헤더(or 트레일러)를 덧붙인 후 하위 계층으로 전달하는데 이 과정이 캡슐화(encapsilation) 역캡슐화는 반대로 메시지를 수신할 때 각 계층에서 헤더를 확인한 뒤 제거하고 상위 계층으로 올려 보내는 과정을 의미
출처 : 한빛출판네트워크 홈페이지 > 채널.H
# 프로토콜 데이터 단위 PDU(Protocol Data Unit) 각 계층에서 송수신되는 메시지의 단위 상위 계층에서 전달받은 데이터에 현재 계층의 프로토콜 헤더(및 트레일러)를 추가하면 현재 계층의 PDU
OSI 계층
PDU
응용
데이터 혹은 메시지
표현
세션
전송
세그먼트(TCP), 데이터그램(UDP)
네트워크
패킷 (간혹 IP 데이터그램)
데이터 링크
프레임
물리
비트
이렇게 해서 "혼자 공부하는 네트워크"의 챕터 1 컴퓨터 네트워크 시작하기 파트를 공부해 봤는데요. 그냥 가기는 아쉬우니 족장님의 추가 숙제📚를 풀어보겠습니다.
# (p35) 확인문제 2번 "네트워크에 대한 설명으로 옳지 않은 것을 골라 보세요" 네트워크에 대한 이해는 프로그램을 만드는 과정에 도움을 주기에 1번 선지가 오답 컴퓨터 네트워크와 인터넷에 대해 설명하면서 프로그램 개발/유지보수 같은 상황에서 네트워크 배경지식을 활용하는 경우가 많다고 언급함
# (p73) 확인문제 2번 "네트워크 참조 모델에 대한 설명으로 옳지 않은 것을 골라 보세요" TCP/IP 모델은 네트워크 액세스, 인터넷, 전송, 응용 계층으로 구성된 4계층 모델이라 2번 선지가 오답
프로그래머스는 블로그 게재 시 문제 여지가 있어 자세한 내용 없이 문제 제목과 링크로 대체합니다.
게임 캐릭터가 제한된 맵(좌표) 내에서 상하좌우로 움직이는 경로의 길이를 계산하는 문제였다.
내 첫 접근법은 1) 좌표니까 계산하기 쉽게 배열을 쓰고 2) 그 다음에 좌표값에 따라 배열마다 횟수를 저장하면 되겠지 였다.
// 이 코드는 정답이 아닙니다 //
class Solution {
public int solution(String dirs) {
int answer = 0;
// 좌표평면 배열
// 배열[5][5]가 좌표평면 (0.0) = 배열 -5하면 좌표 평면 위치가 나옴
int[][] path = new int[11][11];
int x = 5, y = 5;
for (int i=0; i<dirs.length(); i++){
char c = dirs.charAt(i);
switch (c){
case 'U': // 위로 한 칸
if (y<10) {y++;} break;
case 'D': // 아래로 한 칸
if (0<y) {y--;} break;
case 'R': // 오른쪽으로 한칸
if (x<10) {x++;} break;
case 'L': // 왼쪽으로 한 칸
if (0<x) {x--;} break;
}
// 처음 걸어본 길일 때만
if (path[x][y] == 0) {
path[x][y] += 1;
answer++;
}
}
return answer;
}
}
근데 코드를 돌려 보니 실패! 다시 살펴보니 너무 단순하게 생각해 방향성을 고려하지 않았다.
내 코드대로 라면 (0.0) 에서 U 해서 1이 되면 (2.1) 에서 L로 다시 돌아오는 것도 카운트가 안됨...
그래서 바꾼 게 3차원 배열로 방향성을 추가해 주는 거였다. 하지만 가내수공업으로 U/D 또는 L/R을 다 고려해줘야 했고요... 그래서 이렇게 지저분한 코드가 탄생했지요
import java.util.*;
class Solution {
public int solution(String dirs) {
int answer = 0;
// 좌표평면 배열
// 배열[5][5]가 좌표평면 (0.0) = 배열 -5하면 좌표 평면 위치가 나옴
// [][][방향] 0 U, 1 D, 2 L, 3 R
int[][][] path = new int[11][11][4];
int x = 5, y = 5;
for (int i=0; i<dirs.length(); i++){
char c = dirs.charAt(i);
switch (c){
case 'U': // 위로 한 칸
if (y<10) {
path[x][y][0] = 1;
y++;
path[x][y][1] = 1;
} break; // 경로마다 방향은 양쪽 + 처음 걸은 1번만 카운트
case 'D': // 아래로 한 칸
if (0<y) {
path[x][y][1] = 1;
y--;
path[x][y][0] = 1;} break;
case 'R': // 오른쪽으로 한칸
if (x<10) {
path[x][y][3] = 1;
x++;
path[x][y][2] = 1;} break;
case 'L': // 왼쪽으로 한 칸
if (0<x) {
path[x][y][2] = 1;
x--;
path[x][y][3] = 1;} break;
}
}
for (int i=0; i<path.length; i++){
for(int j=0; j<path[0].length; j++){
for(int k=0; k<path[0][0].length; k++){
if (path[i][j][k] == 1) {
answer++;
}
}
}
}
answer = answer/2; // 양방향이라 /2
return answer;
}
}
답안을 보니 이렇게 중복 미포함과 같은 문구가 나올 때는 해시셋을 떠올리라고 하더라 자바의 HashSet은 Set 인터페이스를 구현한 클래스다. 1) 중복된 값을 허용하지 않음 2) 입력한 순서가 보장되지 않음 3) null을 값으로 허용함
대충 로직은 이래서 나랑 비슷하기는 한데... 코드는 훨씬 더 간결하다 심지어 이건 시간복잡도도 N이라서 나중에 다른 문제 풀면서 해시맵/셋을 활용하기 위해 노력해 봐야겠다.
import java.util.*;
private static boolean isValidMove(int nx, int ny){
return 좌표평면 내인지 체크하는 함수 구현
}
// 다음 좌표 결정을 위한 해시맵 생성
private static final HashMap<Character, int[]> location = new HashMap<>();
private static void initLocation(){
// put 함수 사용, 상하좌우에 따른 배열을 생성함
}
class Solution {
public int solution(String dirs) {
initLocation();
int x = 5, y = 5;
// 겹치는 좌표는 1개로 처리
HashSet<String> answer = new HashSet<>();
for (int i=0; i<dirs.length(); i++){
// UDLR을 가지고 매번 새로운 배열 offset을 만든다
int[] offset = locations.get(dirs.charAt(i));
// 그리고 좌표값 nx, ny를 계산함
if (!isValideMove(nx,ny)) continue;
// 범위 벗어나면 패스함
// A에서 B로 간 경우, B에서 A로 간 경우를 해시셋에 추가
// 해시셋에 추가하는 메소드는 .add
// 0 0 >> 0 1
// 0 1 >> 0 0
// 좌표 이동 후 x, y를 업데이트
}
return answer ;
}
}
이렇게 해서 "코딩 테스트 합격자 되기:자바 편"의 첫 번째 파트인 "배열"이 끝났다. 마지막에 풀어 보면 좋을 추천 문제도 알려주더라 - 배열의 평균값 - 배열 뒤집기 - 배열 자르기 - 나누어 떨어지는 숫자 배열 앞에 2개는 풀어봤던 거라, 뒤에 2개만 풀어보고 스택으로 넘어갈 예정이다.
반복해서 포스팅하고 있는데, 내가 보면서 공부하고 있는 책은 "코딩 테스트 합격자 되기:자바 편"이다. 가격은 정가 42,000원이다. (밀리의 서재에도 있음)
프로그래머스는 블로그 게재시 문제 여지가 있어 자세한 내용 없이 문제 제목과 링크로 대체합니다.
책에서 권장 시간 60분이랬는데 넘긴 듯 다음에는 시간도 재면서 풀어봐야겠다.
입출력 예시를 보면, 스테이지 수는 5개이고 총 8명의 사용자가 있습니다. 스테이지별로 아직 클리어 하지 못한 사용자와 도전한 사용자 수를 보면
스테이지 번호
클리어 못한
도전한 사용자
실패율
1
1
8
1/8
2
3
7
3/7
3
2
4
2/4
4
1
2
1/2
5
0
1
0/1
스테이지가 올라갈수록 클리어 못한 사용자의 수를 빼야 도전한 사용자의 수가 나온다! 그리고 나중에 출력은 실패율이 높은 스테이지부터 낮은 스테이지 순으로, 만약 실패율이 0으로 같다면 스테이지 번호가 낮은 것부터 높은 순으로 하라고 되어 있다.
헤매긴 했지만 그래도 혼자서 성공해 낸 내 코드 흐름을 보면
1) 스테이지별 실패율 계산을 위해 fail 이라는 배열을 하나 만들었다 실패율 계산에 나누기가 들어가서 실수형 double을 택함 2) 배열 fail의 순서(i+1)가 스테이지의 순서니까, stages 배열을 돌면서 해당 스테이지를 클리어 못한 사용자를 카운트했다. if (stages[j] == i+1) c++; 3) 그리고 실패율을 계산해서(c/u), fail 배열에 저장했다. 만약 클리어 못한 사용자가 없으면 실패율은 0이니까 바로 0으로 저장해 줬다. 4) 그리고 도전한 사용자 수에서 현재 스테이지에 남아있는 사용자 수(u-c)를 빼줬다.
스테이지 번호 fail[i]
클리어 못한 사용자 stages[j]의 수 == i+1 c로 카운트 올림
도전한 사용자 u
실패율 c/u로 계산 fail에 저장
5) 그리고 스테이지 순서대로 실패율을 저장해 놨기 때문에 clone 해서 sort로 내림차순 정렬을 했다. 근데 내가 사용한 배열은 기본 primitive 타입 double 이라서 Collections.reverseOrder()를 쓰기 위해 래퍼 wrapper 타입으로 형 변환을 해줬다. 6) 그리고 기존 배열과 제일 높은 순으로 정렬된 배열을 비교하면서 스테이지 순서를 조건에 맞게 fail_s 배열에 추가해 줬다.
실제로 작성한 코드는 이렇다
import java.util.*;
class Solution {
public int[] solution(int N, int[] stages) {
int[] answer = {};
// 스테이지 번호로 멈춘 수를 카운트
int s = N;
int u = stages.length; // 유저 모수 계산용
double[] fail = new double[s]; // 실패율 계산용 배열
// 스테이지별 실패율을 계산하면서, 전체 인원수를 줄여나감
for (int i=0; i<fail.length; i++){
int c=0;
for (int j=0; j<stages.length; j++){
if (stages[j] == i+1){ // 스테이지는 1번부터라 i+1
c++; // 해당 스테이지에 있는 사용자만 세기
}
}
if (c==0) {fail[i]=0;}
else {fail[i] = (double) c/u;}
u = u - c;
}
// 실패율을 비교해서 높은 스테이지 >> 낮은 스테이지. 실패율이 0이면 오름차순으로
double[] clone = fail.clone();
Double[] cd = Arrays.stream(clone).boxed().toArray(Double[]::new);
Arrays.sort(cd, Collections.reverseOrder());
ArrayList<Integer> fail_s = new ArrayList<>();
for (int i=0; i<cd.length; i++){
for(int j=0; j<fail.length; j++){
if (cd[i] == fail[j]){
fail_s.add(j+1);
fail[j] = -1;
break;
}
}
}
answer = fail_s.stream().mapToInt(Integer::intValue).toArray();
return answer;
}
}
이것보다 더 예쁘고 간단하게 코드짤 수 있을 것 같은데... 모르겠다 ㅋ
암튼 이 코드에서 배운 점은 내림차순 정렬은 일단 Arrays.sort(배열명, Collections.reverseOrder())을 사용한다. 하지만 기본 타입 배열에는 적용이 불가능하다. *기본 타입: byte, char, double, short, long, int, float ...
그래서 래퍼 클래스로 만든 다음(boxing) 정렬해야 한다. *래퍼 클래스: 기본 자료형의 데이터를 인스턴스(객체)로 만들기 위해 사용하는 클래스 Byte, Character, Double, Short, Long, Int, Float ...
double[] clone = fail.clone(); Double[] cd = Arrays.stream(clone).boxed().toArray(Double[]::new);
내가 공부 중인 책에서는 스테이지별 도전자 수/실패한 사용자 수를 추출하고, 그리고 해쉬 맵을 사용 해서 풀었더라 대략적인 흐름만 따라가 보자면
// 스테이지별 도전자 수를 구하는 부분
// 0번째 인덱스는 사용하지 않고, 마지막 스테이지까지 클리어한 N+1 고려
int[] chal = new int[N+2];
for 문
// 스테이지별 실패한 사용자 수 계산
// 해쉬맵의 키는 스테이지 번호, 값은 실패율
HashMap<Integer, Double> fails = new HashMap<>();
double total = stages.length;
// 각 스테이지를 순회하며 실패율 계산
for (int i = 1; i <= N; i++){
if 도전한 사람이 없는 경우 {fails.put(i, 0.);}
}
else{ // 있는 경우에는 실패율 계산
fails.put(i, chal[i] / total);
현재 스테이지 인원 빼기
}
// 실패율이 높은 스테이지부터 내림차순 정렬하기
return fails.entrySet().stream().sorted((oa, o2)
-> Double.compare(o2.getValue(), o1.getValue())).mapToInt(HashMap.Entry::getKey).toArray();
자세한 건 책을 직접 확인하세요 책 이름은 "코딩 테스트 합격자 되기: 자바편"입니다.
해쉬맵은 데이터를 추가할 때는 put(key, value) 모든 데이터 삭제할 때는 clear() remove(key)는 key와 일치하는 기존 데이터 삭제 remove(key, value)는 key와 value가 동시에 일치하는 데이터 삭제 entrySet() : 모든 key-value 매핑 데이터를 가진 set를 반환
자바 스트림 Stream은 Java 8부터 추가된 기술로 람다를 활용해 배열과 컬렉션을 함수형으로 간단하게 처리 최종 연산 전까지 중간 연산을 수행하지 않는다. 작업을 내부 반복으로 처리한다.
.filter() > 스트림 내 요소들을 하나씩 평가해 걸러내는 if문의 역할 .sort() > 스트림 내 요소들을 정렬하는 작업. Comparator 사용 .distinct() > 중복 제거
이걸 조금 더 고급지게 정리해보자면 A 행렬의 크기가 (m * k), B 행렬의 크기가 (k * n) 일 때 두 행렬의 곱 연산 결과는 m * n 이 됩니다. A의 행의 개수 k와 B의 열의 개수 k를 기준으로 곱하기 때문이에요. 그래서 k는 똑같아야 해요. 이번 문제에서는 곱할 수 있는 배열만 주어진다는 조건을 걸어 k가 똑같다는 걸 알려줬는데요. 만약 이런 조건이 없다면 두 k를 비교해 곱하기가 가능한지 고려하는 연산도 추가해야 합니다.
다시 문제로 돌아와서
class Solution {
public int[][] solution(int[][] arr1, int[][] arr2) {
int r1 = arr1.length;
int c1 = arr1[0].length; // arr1의 행과 열 계산 c1 = k
int r2 = arr2.length; // c1 = r2 = k
int c2 = arr2[0].length; // arr2의 행과 열 계산
// 결과 행렬 크기는 앞쪽 행렬의 행(r1) * 뒷쪽 행렬의 열(c2)
int[][] answer = new int[r1][c2];
for (int i=0; i<r1; i++){ // arr1의 각 행
for (int j=0; j<c2; j++){ // arr2의 각 열을 반복하는데
for(int k=0; k<c1; k++){
// 두 행렬의 데이터를 곱해야 하는데 k가 반복되어야 함
answer[i][j] += arr1[i][k] * arr2[k][j];
// [0][0] = [0][0] * [0][0]
// [0][0] = [0][1] * [1][0]
// [0][1] = [0][0] * [0][1]
// [0][1] = [0][1] * [1][1]
}
}
}
return answer;
}
}
수학적 사고력이 없는 과거의 수포자 인간이라 힘들었따^^ 이 문제는 무조건 나중에 다시 풀어봐야지
프로그래머스는 블로그 게재시 문제 여지가 있어 자세한 내용 없이 문제 제목과 링크로 대체합니다.
문제 설명부터 너무 나를 위한 거라 마음에 들더라? (아무도 안 믿지만 과거의 수포자)
패턴이 정확히 있고 하니까 정답 배열이랑 비교해서 맞은 개수 카운트 하면 되겠네 하고 가볍게 시작했는데 나중에 보니 가장 많은 문제를 맞힌 사람을 숫자로 표현해줘야 했다. 그게 좀 까다롭(?)다.
import java.util.*;
class Solution {
public int[] solution(int[] answers) {
int[] answer = {};
int[] sa1 = {1, 2, 3, 4, 5}; // 5개
int[] sa2 = {2, 1, 2, 3, 2, 4, 2, 5}; // 8개
int[] sa3 = {3, 3, 1, 1, 2, 2, 4, 4, 5, 5}; // 10개
int[] score = new int[3]; // 점수 계산용
ArrayList<Integer> ans = new ArrayList<>();
int s1 = 0, s2 = 0, s3 = 0;
for (int i=0; i<answers.length; i++){
// 1번 학생의 패턴인 1~5 순서대로 반복하면서 비교
if(sa1[s1]==answers[i]) {score[0]++;}
s1++;
if(s1==5) {s1=0;}
if(sa2[s2]==answers[i]) {score[1]++;}
s2++;
if(s2==8) {s2=0;}
if(sa3[s3]==answers[i]) {score[2]++;}
s3++;
if(s3==10) {s3=0;}
}
// 가장 많이 맞춘 학생의 점수 찾기
int max = Arrays.stream(score)
.max().getAsInt();
// 최고점과 각 학생의 점수 비교해서, 순서찾기
// 다 같이 점수가 동일한 경우에는 어차피 1번 학생부터 add됨
for (int i=0; i<3; i++){
if (max == score[i]){
ans.add(i+1);
}
}
answer = ans.stream().mapToInt(Integer::intValue).toArray();
return answer;
}
}
오 책의 예시 답안을 보니 접근방법은 나랑 비슷한데, 훨씬 더 깔끔하게 풀어내셨다.
import java.util.*;
class Solution {
public int[] solution(int[] answers) {
int[] answer = {};
// (나랑 다른 부분) 패턴을 이렇게 2차원 배열에 넣었다.
int [][] pattern ={
{1, 2, 3, 4, 5}, // 5개
{2, 1, 2, 3, 2, 4, 2, 5}, // 8개
{3, 3, 1, 1, 2, 2, 4, 4, 5, 5}; // 10개
}
// (동일) 점수 저장할 배열을 만들었다
int[] score = new int[3]; // 점수용
// 각 수포자의 패턴과 정답이 얼마나 일치하는지를
// for문 2개에 구성해서 표현했다.
// 이게 핵심이니까 여기는 필요하면 책을 찾아보세요.
// (동일) 가장 높은 점수를 찾고
int max = Arrays.stream(score)
.max().getAsInt();
// (동일) 가장 높은 점수를 가진 사람들을 찾아서 리스트에 담는다.
for (int i=0; i<3; i++){
if (max == score[i]){
ans.add(i+1);
}
}
answer = ans.stream().mapToInt(Integer::intValue).toArray();
return answer;
}
}
공부에 참고한 책 이름은 김희성 님의 "코딩 테스트 합격자 되기 자바편"입니다.
오늘의 챌린지 문제 2개를 풀면서 내가 느낀 것은
1. 어레이 리스트 할당하는 법과 >> ArrayList<Integer> sums = new ArrayList<>(); 2. 스트림 메서드를 활용하고 >> Arrays.stream(score).max().getAsInt(); 3. 또 변환하는 법도 알아야 한다는 사실 >> sums.stream().mapToInt(Integer::intValue).toArray();