작년 4월 초에 우연히 식목일 기념 나무 심기 프로젝트 광고를 보게 되었다. 내가 나무 심을 돈을 기부하면 기업에서도 절반을 부담해 서울 각지의 공원에 나무를 심어준다는 내용의 프로젝트였는데, 식목일도 다가오니까 하면서 작게 기부를 했었다. 근데 올해 또 한다고 문자가 왔길래 이번에는 포스팅을 남겨본다.
바로 생명의숲이 운영하는 "서울마이트리"라는 프로젝트인데, 작년에 이어 올해도 현대백화점의 Green Friends 캠페인과 함께 진행한다고 한다. 작년이 처음인지 아니면 그전에도 계속하던 프로젝트인지는 잘 모르겠다.
클릭하면 기부 프로젝트 사이트로 이동해요
작년도 프로젝트 성과를 소개하고 있길래 가져와봤다. 작년 기부 참여자는 나 포함 총 2,472명, 식재수량은 교목 561주 + 관목 4,929주로 총 5,490주!
프로젝트 이름이 "서울마이트리"이기 때문에 작년에 기부된 나무는 서울 소재 12개 공원에 심겼다고 한다. 올해는 작년보다 줄어든 8개 공원에서만 진행하나보다.
올해 대상인 공원 위치와 이름은 다음과 같다.
나는 작년에는 마포에 있는 월드컵공원에 미스김라일락 나무를 심었다. 미스김라일락은 진짜로 한국인 '미스 김'의 성을 따서 붙인 이름이라고 한다. 나무에 이름도 따로 붙일 수 있었는데 뭐로 했는지 기억이 안 난다. 식재 완료되고 나면 내 나무 심긴 위치 같은 것도 대략적으로 알려준다. 월드컵공원 갈 일이 없어 아직 내 나무를 보러 간 적은 없는데, 나중에 찾아가 봐야지.
이 프로젝트가 유지되는 한 매년 할 생각에 올해는 다른 공원을 골랐다. 1년에 1개씩 공원 하나하나 다 채우는 게 목표 ^ㅁ^ 나무 이름에 통일성을 부여하려면 작년에 무슨 이름이었는지 기억해내야 하는데 가족 단톡방이며 여기저기 찾아봐야겠다...
참여방법은 엄청 간단하다. 우선 생명의 숲 서울마이트리 사이트나 현대백화점 프로젝트 사이트에 들어간다.
그리고 심고 싶은 나무와 공원의 위치를 고르면 된다. 공원별로 정해진 나무가 다르니까 그건 개별 페이지 체크하면 된다. 그리고 기부금을 결제하면 되는데, 나무에 필요한 나머지 비용 절반은 현대백화점이 부담한다.
기부금 영수증이 필요하다면 나중에 생명의 숲에서 보내는 안내 문자를 참고하면 되고, 나무를 직접 심고 싶다면 행사참여 안내 문자가 왔을 때 신청하면 된다. 저는 다 심기면 구경만 갈게요... 제가 식물을 좋아하기는 하는데 식집사는 절대 못할 인간이더라고요. 집에서 간단 키트로 바질 키웠는데 싹 틔운 지 3일 만에 가버렸음ㅠㅠ 바질아 미안해ㅠㅠ
이상 서울마이트리 내 나무 갖기 기부 프로젝트 포스팅을 마무리한다. 너무 대충 포스팅하고 마무리하는 느낌이라 민망하긴 한데,,, 내년에 또 기부할 나를 위해 대충 어디 어디에 심었다를 기록하기 위한 용도였다^^
혼공단 13기 참여 예고 글을 올린 게 엊그제 같은데 벌써 2달 전이라죠 6주가 쏜살같이 지났습니다 다행히 예고한 대로 책 1권 뿌시기에 성공했어요 일단 냅다 박수~!~!
그럼 혼공단 13기 활동 회고 시작해 볼까요 시작은 상큼하게 족장님이 응원의 글로 올려주셨던 복리 효과 짤 하루하루를 보내다 보면 아무것도 안 한 것 같지만 그 작은 하루들이 1년 뒤에는 꽤나 큰 차이를 만들어낸다. 뭐든 꾸준히 하다 보면 언젠가 성장한다는 이런 내용이다. 비단 돈에만 적용되지 않는 인생에도 충분히 적용될 수 있는 재테크 공식이라죠.
혼공단 하길 진짜 잘했다고 생각한 점은요
일단 네트워크 이론을 한 바퀴 돌리면서 공부를 할 수 있었다!
아무도 시키지 않은 이전 내용 복습하기 콘텐츠까지 하면서 정리했는데, 기억에 얼마나 남을지는 모르겠지만 전공 지식을 다시 쌓아 올리는 시간이었던 거 같아요 단어로는 알고 있지만 누군가 갑자기 설명해 봐! 그래서 그게 뭔데! 하면 어버버 했을... 그런 익숙한 듯 친숙한 듯 하지만 그렇지 않은… 항상 거리감 느껴지던 개념들과 조금은 가까워진 느낌이에요 나 다시 도비 될 때까지 친하게 지내자 친구들^^ 내 최애기업은 서술형 시험을 봐… 전공시험처럼 뇌에서 냅다 뽑아서 줄줄줄 적어야 해… 잘 부탁해…
말이 조금 샜는데 책 1권을 공부하면서 네트워크 기초 지식을 다시 습득했고 연관된 개념들도 찾아보며 추가 공부도 하는 유익한 시간이었다~
잘했다고 생각하게 된 두 번째는
다른 사람들 공부하는 걸 볼 수 있다! (자극과 추가공부)
족장님이 숙제 검사하고 나면 각자 공부한 내용의 장점만 부각해서 소개해주거든요. 사람마다 공부하고 정리하는 스타일이 진짜 다 달라서 심심할 때 다른 사람들 꺼 구경하면 또 재밌어요 그 김에 개념들도 한 번 더 상기할 수 있고 일석이조~!
어떤 분은 혼공 책과 전공서적을 같이 보기도 했대요 아무래도 혼공 책이 기본기에 충실한 책이다 보니 철저한 심화학습을 추구하신 것 같은데 좋은 아이디어…! 많은 노력이 들어가겠지만 6주간 책 2권을 병행한 사람이잔아 개이득이잔아?
벤치마킹하려고요^^7 14기에는 컴퓨터구조+운영체제 하고 싶은데… 전공서적이랑 병행 가능한 분량인가 근데? 내 기억상 엄청나게 많았는데...?! 혼공단 전에 혼공컴운 혼자 읽어본 사람임
한빛미디어 책으로 전공 공부 커리를 짠다면, 이렇게 추천
아 여담으로 요새는 아예 비전공자 분들도 컴퓨터 공학 공부 많이 하기도 하고 잃어버린 전공 지식을 되살리려는 저 같은 사람들도 많은데요 초장부터 정보처리기사 같은 재미없는 자격증 책으로 공부하기 어렵잖아요? 이렇게 해보시는 거 어떤가요
[1안 세세 to 구조 잡기] 혼공네트랑 혼공컴운을 개별로 하나씩 보면서 세세하게 공부를 하고 마지막 정리하는 느낌으로 이것이 컴퓨터 과학이다를 보는 루트구요,
[2안 구조 잡기 to 세세] 반대로 이것이 컴퓨터 과학이다를 먼저 보면서 전체 개괄을 잡고 개별 도서를 하나씩 세세하게 파는 루트도 괜찮을 거 같아요.
전공자인 제가 세 책 모두 읽어보고 남기는 의견입니다 여기서 부족하다 하시면 SQL과 각자 공부하는 개발 언어책 하나 추가하면 베스트!
사실 저는 저 책들 읽어보다가 혼공학습단을 알게 되었고 첫 활동이니까 제일 만만한 네트워크를 먼저 고르게 되었거든요 근데 혼공단 뿌듯하고 재밌어서 계속 해나가려구요
글애서 말인데 족장님 도서 이름이 혼공은 아니지만 '이것이 시리즈'도 혼공단 같은 콘텐츠 해주세요,,, 혼공 시리즈 내용을 총망라 또는 심화학습 하는 느낌의 책들이자나요~!
잘했다고 생각하게 된 세 번째 장점은
혼공단은 지치지 않게 계속 격려받을 수 있다! (누군가의 따순 응원)
족장님이 매주 숙제 검사를 빙자한 무한 칭찬을 뚱댓으로 해주고요, 가끔씩 잘했다고 간식도 주고요, 운 좋으면 책도 줘요. 공부 다 하잔아? 그럼 다른 책 공부할 수 있게 책 사라고 마일리지도 줌. 진짜 안 할 이유가 없다…🫡
혼공단 활동 끝나는 게 너무 아쉬운데 보통 혼공단이 반기에 1번 열리는 것 같더라구요 그래서 혼공단 비수기(?)에는 개인적으로 다른 책들 공부하고 정리하는 시간을 가져볼까 해요 또 블로그 특으로 계획만 거창해지는 중
혼공단 성공적으로 마치면 주시는 마일리지로 책을 사서 보면 어떨까 생각만 하고 있는데요. 제 후보군은 이 셋입니다 어느 게 나을지 누군가 이 글을 보고 계시다면 추천 환영
책 찾다 보니 한빛 공홈에서 ebook으로도 구매 가능하네? 패드로 모든 걸 하는 전자인간에게 완전 딱 맞춤이네...
아무튼 작년 12월에 돌아온 도비 시즌을 맞이해 이것저것 계획을 엄청 세우고 포부가 가득한 인간이었는데요,,, 혼공단이라도 끝낸 기념으로 중간 점검을 해보자면요
첫째, ⭐️혼공단 성공⭐️
둘째, 사회조사분석사는 필기 합격(실기 남음) 셋째, 정보보안기사(발등에 불 떨어짐^_^ 할 수 있다 아좌아ㅈㅏ) 넷째, 블로그에 썼던 코테풀이 챌린지는 거의 작심삼일 하고 지금은 스파르타 코딩클럽에서 알고리즘 스터디로 대체 중… 이거 끝나면 다시 진행시켜 보기로 했어요 다섯째, AI 공부는 교양서들 독서 끝내고 생성형 AI와 친해지고자 부스트코스 통해 스터디 진행 중 내용 공유가 불가한 스터디라 나중에 후기만 찔 예정 여섯째, 언어 공부 어플 꾸준히 사용하기는 성공 중
그 외 개인적인 취미와 자기만족용 활동들도 킵고잉 중입니다 나 집 도비가 천성에 맞는데 평생 하고 싶다
마지막으로 지금 새롭게 고민 중인 활동이 하나가 있는데요 요즘 핫한 Cursor AI 공부하는 2주짜리 챌린지인데 내가 신청해 둔 정보보안기사 일정이랑 너무 겹쳐서 고민이 깊어지는 순간입니다
흠 적어놓고 보니 포스팅 초반에 했던 말처럼 일상에서 소소하게 무언가를 계속하고는 있네요. 어쩌면 (1.01)^365식 인생 재테크 순항중일지도... 이것저것 셀프고문 콘텐츠 만들어두길 잘했다는 생각이 드네요 맨날 속으로 과거의 나 새끼😡 이러면서 살기는 하지만 글애도 집 도비라 너무 나태해질까 봐 걱정했는데 이 정도면 부지런한 집 도비가 된 것 같구만
사실 재취업에 초점을 놓고 본다면 컴퓨터 일반 같은 수험서랑 NCS, 코딩테스트만 냅다 조져야 하지만 그러기엔 재밌어 보이는 것도 해보고 싶은 것도 너무나도 많은 탐욕 인간인지라^^ㅋ 뭐 그래도 지금까지 살면서 이렇게 하나둘 욕심으로 시작한 게 다 언젠가는 도움이 되었어요 쓸모도 있었고 혼공단만 봐도 네트워크 공부 해냈자나 최고자나 그러니 내 방식대로 킵고잉~ 다만 코테 공부는 조금만 더 힘줘서 노력합시다🙏🏻
필기 공부 하기 싫어서 회피용으로 신청했던 자격증 사회조사분석사 2급 필기를 보고 온 기념으로 후기를 남긴다 시스템상 가채점 결과가 70점이니까 합격이겠지^^ 근데 회피형 레전드인 게 지금은 2주 남은 정보보안기사 필기 공부하기 싫어서 블로그 씀^^ㅋ 아무튼 사회조사분석사는 회사 다니며 알게 되었는데 회사에서도 설문조사 기획하고 수행할 일이 많다 보니 공부해 두면 좋지 않을까 생각해서 눈여겨보던 자격증이었다 근데 알고 보니 필기 1번에 실기 2번 해서 총 3번 시험 봐야 하더라? 만약 취업을 위한 서류전형 가점 등을 위해 본시험을 준비하시는 분이 계시다면 가성비가 매우 떨어지니 다른 자격증 시험을 먼저 고려하세요,,, 시험 3번 봐야 자격증을 줘요 비슷하게 언급되는 자격증으로 ADsP가 있는데 걔는 1번만 보면 자격증 주거든요,,,
시험 개요
사회조사분석사는 다양한 분야에서 사회 구성원 또는 고객을 대상으로 시장조사, 여론조사 등의 계획 수립과 조사를 담당하며, 이를 통해 얻은 결과를 검토 분석하는 역할을 수행합니다. 그래서 이 자격증을 따면 통계직 공무원 시험에 가산점을 주거나 공기업 등 다양한 기업에서 서류 전형에 가점을 주기도 하더라구요
시험 상세
위에도 언급했지만 시험을 총 3번이나 봐요
구분
방법
문항 수
시험시간
응시료
필기
객관식 4지선다 (CBT)
100문항
2시간 30분
19,400원
실기
필답형 + 작업형
-
필답형 2시간 작업형 2시간 가량
33,900원
필기시험 과목 및 문항수
필기시험은 총 3과목인데 마지막 통계분석과 활용 과목이 40문항으로 점수 배점이 더 크다 이 3과목이 통계학 내용이라 제일 어렵기도 함 과락이 있는 시험이기 때문에 각 과목별로는 40점 이상, 전 과목 평균은 60점 이상을 득점해야 합격할 수 있다
과목명
문항수
과락 방지 기준
최소 합격 기준
안정 합격 기준
1 조사방법과 설계
30문항
13문항 이상
22
24
2 조사관리와 자료처리
30문항
13문항 이상
22
24
3 통계분석과 활용
40문항
16문항 이상
16
20
총계
100문항
(불합방지) 61문항 이상
보통은 맞은 문항 수로 계산을 많이 하더라 많이들 생각하는 최소 합격과 안정 합격의 기준도 표에 적어뒀다 아무래도 3과목이 제일 득점하기 어렵다 보니 1과목과 2과목에서 고득점을 하는 전략을 많이 사용한다 나도 그랬음
2025년도 시험 일정
내가 본 건 올해 1회차였구요 아직 5월과 8월에도 기회가 남아 있읍니다 여러분
본격적인 공부 방법 남기기에 앞서 내 점수를 공개하자면 73 / 86 / 52 = 총점 70 이건 공부하면서 회차와 문제풀이 일자별 점수를 계산했던 건데 실제 시험 결과랑 비교해 보면 1과목이 현저하게 낮아졌다
의외로 1과목이 초면인 선지도 있고 어렵게 느껴졌고 3과목은 23년도 복원 기출이랑 비슷한 문제도 서너 개 본 거 같다 문제은행 아닐지라도 최신 기출은 꼭 풀어보기를 추천
공부 기간 : 약 3주
공부 기간은 띄엄띄엄해서 약 3주 정도이다 통계학 베이스가 없는 + 수포자 인간이라 걱정돼서 조금 일찍 시작함 근데 초반 2주는 개념서 읽고 정리하느라 쉬엄쉬엄했다 그리고 나머지 1주는 상기 표에서도 보이듯 그냥 문제만 한 회차씩 풀고 오답하고 그랬다
공부 방법 : 시대고시 문제집 위주
사실 그냥 시험 봐야지라고 생각만 하면 안 할까 봐 내배카로 강의를 하나 결제했었다 의지와 끈기를 돈으로 주고 사려는 계략이었는데 나는 개인적으로는 비추다^^ 일단은 같이 제공해 주는 책이 오타도 많고 별로였고 원래도 독학으로 공부를 더 많이 해 버릇해서 그런가 딱히 재미를 느끼지 못해 열심히 듣지는 않았다^^ 그냥 약 십만 원에 공부 의지를 산 사람만 되었음... 내 돈...ㅠ
대신 주로 공부한 교재는 밀리의 서재에 올라와 있는 시대고시 책 2권이었다
개념은 "2024 SD에듀 Win-Q 사회조사분석사 2급 필기 단기합격"이라는 책으로 봤다 요약된 핵심이론과 그에 맞는 기출문제들 2-3개씩 풀어볼 수 있다 나는 핵심이론을 문제 풀면서 내 식대로 단권화해서 봤다 나만의 요약집은 조금 정리를 거친 후에 추후 공유 예정 혹시 궁금하신 분들은 댓 남겨주시면 미리 공유드릴게요~
그리고 문제풀이는 "2023 사회조사분석사 2급 1차 필기 기출문제해설"이란 책으로 봤다 보다시피 2018~2022년도 기출뿐이라 최신까지는 아니지만 종이책 사기 귀찮아하는 나에게는 딱 좋은 선택지였던 것 같다 종이책으로는 2024년도 기출까지 다 담긴 개정판 있지 않을까? 개인적으로 이 책에 아쉬웠던 점은 문제 바로 아래 해설이 있다는 거... 나도 모르게 자꾸 눈길이 가서 손바닥으로 가리면서 풀었다^^ 이건 개인 취향이니까 뭐 참고하시라
아무튼 다들 왜 자격증 공부할 때 밀리의 서재 안 써요? 사회조사분석사라고만 검색해도 책이 10권이나 나온다 진심 아무리 생각해도 꿀이다
아 그리고 요새 "밀리의 서재 연말정산"이란 키워드로 유입이 많은데 밀리는 책 구매가 아니라 구독이라 연말정산 문화비 소득공제 비대상입니다 FAQ에서 가져온 내용 참고하세요~~ 비슷한 플랫폼 서비스인 리디셀렉트도 동일할 듯합니다
아무튼 시험 형식이 CBT다 보니 익숙해지는 게 좋을 것 같아 기출문제를 온라인에서 풀 수 있게 제공하는 사이트에서도 문제를 풀어보기는 했다 (다른 자격증으로도 유명한 https://www.comcbt.com) 사실 많이는 아니고 두 번... ㅎㅎ 점수 계산이 편한 건 좋더라
참고로, 나처럼 엑셀이나 구글 스프레드 시트 사용해 점수 계산이 귀찮다면 챗지피티(ChatGPT)를 부려먹는 방법도 있다. GPT한테 시키잖아요? 기가 맥히게 해 오고 전략 분석도 해줘요^^
GPT 계산을 원하시는 분들은 아래 문구를 복붙해서 사용하시면 편해요 더 수정해서 회차별 등락도 분석할 수는 있을 것 같은데... 나는 귀찮아서 계산까지만...
GPT야 내가 1과목 ___개, 2과목 ____개, 3과목 ___개 해서 맞은 문제 개수를 알려주면 각 과목별 점수와 전체 평균을 계산해서, 과목별 과락 여부와 전체 합격/불합격 여부를 계산해서 알려줘
1과목과 2과목은 각각 문제가 30개이고, 하나당 배점은 3.3333이야. 3과목은 문제가 40개이고, 하나당 배점은 2.5야. 전체 평균은 과목 3개 점수를 더해서 3으로 나눠.
과목별 과락 기준은 40점 미만이면 과락이고, 합격 기준은 전체 평균이 60점 이상이고, 세 과목 모두 과락이 아니어야 해
GPT는 모르는 문제 풀 때도 엄청 유용해요 개념 문제는 할루시네이션 현상이 가끔 있어서 별로고 이런 계산 문제 잘 모르겠다고 물어보면 기깔나게 알려줍니다 유용함 추천함 GPT야 오래오래 건강해야 해
이외에도 공부 방법 찾아보면서 발견했던(?) 유명한 유튜브나 정보 얻을 곳들을 소개하자면 1) 네이버 카페 사회조사분석사 (S&Y) [조사/통계/SPSS/분석] 같은 분이 유튜브도 운영하심
2) 유튜브 채널 통계는에이스
3) 유튜브 채널 우주잠만보
마지막으로 공학용 계산기 가져갈지 말지 고민하시는 분들께... 안 사셔도 괜찮아요 비싼데 돈 아끼세요...
시험장 컴퓨터에 자체 계산기 프로그램이 있다고 해서 그거 쓰려고 공학용 계산기를 안 사고 그냥 갔거든요 근데 루트 계산도 되고 괜찮았어요 공학용 계산기 없어도 충분히 커버되는 정도였답니다 다만 계산기를 옆에 두고 공부하시던 분이면 갑자기 프로그램으로 계산하려면 약간 낯설게 느껴질 수도 있잖아요? 저는 아이패드 계산기를 공학용으로 바꿔서 사용하거나 온라인 공학용 계산기 사이트 Desmos 사용했어요 추천합니다
언어 공부 어플 1년간 꾸준히 사용하기 프로젝트 두 번째는 AI가 떠먹여 주는 영어회화 앱 플랭(Plang) 이다
이것도 듀오링고처럼 50일 달성 기념으로 포스팅 준비했다죠 연속 학습 보호막 없이 달성한 거 보이시나요 뿌듯 🤓 근데 방금 알았는데 캘린더에서 구슬 누르면 그날 그날 내가 학습한 내용을 볼 수 있다 이런 숨겨진 기능이 있었다니
플랭도 듀오링고처럼 바탕화면에 위젯을 설치할 수 있다 부엉이랑 다르게 귀여운 애벌레 같은 캐릭터가 응원해 준다 얘는 화는 잘 안 내고 놀라거나 삐지기만 함 근데 얘는 이름이 뭐예요 선생님덜 공홈에 정보가 없네
요금제
플랭은 듀오링고와 달리 무료 버전은 없다 무료 체험만 가능한데 써보니 괜찮아서 구독을 하기로 결정했다 요금제는 프리미엄과 부스트로 나뉜다 프리미엄은 나 혼자 또는 파티를 모아 저렴하게 사용 가능한 기본 버전이고, 부스트는 정교한 개인화를 위한 워밍업 테스트+더 좋은 AI 모델을 갖춘 모델이다
요금제
월 구독
연 구독
쉐어 여부
프리미엄
29,000 - 2인 쉐어시 6,459원 - 4인 쉐어시 6,021원
99,000 - 2인 쉐어시 77,500 - 4인 쉐어시 72,250
가능(2인 또는 4인)
부스트
69,000
239,000
불가
플랭 프리미엄 파티로 2인 또는 4인 파티를 모으면 1인당 부담해야 하는 금액이 월 6000원대로 확 낮아진다
사실 그간 회돈내산 내돈내산으로 스픽, 케이크, 튜터링 같이 다른 영어회화나 전화영어 앱들도 써봤었는데 나한테 제일 잘 맞는다고 생각해 플랭을 고르게 되었다 (아래는 제 성향에 따른 개인적인 의견임니다)
스픽은 강의를 들으면서 계속 따라 해야 하는데 그게 생각보다 오래 걸려 큰 부담이었고, 케이크는 영상은 재밌어서 계속 보기는 하는데 따라 말하기나 이런 부분은 강제성이 덜해서 공부한다는 느낌이 덜했다 튜터링은 글로벌 튜터들과 주로 대화했는데 튜터마다 편차가 크기도 하고 잘하고 인기 있는 튜터랑은 자주 대화하기가 힘들었다 게다가 대화가 매번 리셋되는 느낌이라 초반에 스몰톡 하는 시간도 있어 쓰는 영어만 쓰게 되고 영어가 성장한다는 느낌은 받지 못했다
플랭이 마음에 들었던 점은 내 여유 시간에 따라 공부할 콘텐츠 길이를 조절할 수 있다는 거였다. 가볍게, 여유롭게, 적당하게, 열심히, 열정적으로 5개 단계 중 고를 수도 있고 내가 하고 싶은 학습을 직접 설정할 수도 있다.
학습 내용은 구성은 아래와 같다. 1) 영상 속 문장을 공부하는 맞춤 문장 트레이닝, 2) 내가 부족한 발음을 코칭해 주는 AI 발음 코치, 3) 질문 1개에 대답하는 데일리 프리토킹, 4) 질문 5개 정도에 대답하는 AI 라이브챗
학습 내용 1 : 맞춤 문장 트레이닝
짧은 드라마나 유튜브 영상을 보면서 중간에 표현 하나를 공부하는 기능이다 맨 처음에는 영상 중간에 들어갈 문장을 직접 영작해야 한다 그 후에 AI가 내 문장의 뜻과 뉘앙스가 적정한지를 원 문장과 비교해서 설명해 준다
영작하다 보면 내가 비슷한 표현만 자꾸 사용한다는 걸 깨달을 수 있더라 근데 플랭에서는 같은 표현을 마스터할(외울) 때까지 여러 방법으로 복습시켜 주니까 조금이라도 표현력이 느는 기분이다
게다가 원어민들이 자주 사용하는 표현은 AI 코칭이라고 해서 실생활에서 어떤 식으로 사용되는지도 자세하게 보여준다 그리고 문장에 다시 나올 때마다 복습해 볼 수도 있음
가끔씩 내가 부족한 부분을 분석해서 새로운 커리를 추천해주기도 한다 그럼 트레이닝 코스에 추가해서 또 문장을 추천받아 연습하면 된다 이렇게 다양하게 트레이닝 받아볼 수 있다죠 저 동그라미 표현 누르면 강의도 볼 수 있고(이건 안 해봄) 표현과 관련해 내가 학습한 문장들도 모아두었다 보면서 랜덤으로 다시 복습도 가능함
학습 내용 2 : AI 발음 코치
문장을 말할 때마다 내 발음을 AI가 평가해 준다 단어별로 정확히 발음했는지 %가 나오고, 성우 발음과 내 실제 발음을 계속해서 반복해서 들으며 비교도 할 수 있다 나는 얼마 전 영어발음 테스트에서 코리안 100%가 나온 토종 한국인인데 이렇게 발음도 조금씩 교정받을 수 있으니 좋은 것 같다
이렇게 발음하는 법을 우선 강의로 알려주고, 그다음에 단어와 연습문장으로 발음을 하나하나 연습하고 평가받을 수 있다
처음 발음 코치 했을 때 완전 간장공장콩장장 재질이라 놀랐다 말하다가 내 발음이 너무 웃겨서 현타오기도 했음,,,ㅠ
학습 내용 3&4 : 데일리 프리토킹과 AI 라이브챗
데일리 프리토킹과 AI 라이브챗은 진행방식 자체는 비슷하다 친구와의 대화나 잡 인터뷰 같은 상황을 가정하고 질문에 답을 하는 형태인데 AI 라이브챗은 질문 개수가 5개 정도로 하나의 주제에 대해 긴 대화를 하는 형태라면 데일리 프리토킹은 질문이 하나라 상대적으로 짧은 편이다
주제는 내 선호도를 반영해 선정되고 혹시라도 마음에 들지 않는, 내키지 않는 주제가 나온다면 학습 전에 변경도 가능하다
다만 아쉬운 점은 AI가 제약이 있다 보니 너무 길게 말하면 내가 말한 내용의 뒷부분이 잘린다는 점 그리고 간혹 AI가 내 의도를 잘못 해석해 피드백을 엉뚱한 문장으로 제시하기도 한다는 점이다 이건 AI가 계속 개선될 테니 일단은 꾸준히 써보려고 한다
또 다른 아쉬운 점은 직접 말할 수 없는 상황에서는 타자를 쳐서 학습할 수 있게 해 두었는데 간혹 잘못 누르면 이렇게 아무것도 입력되지 않은 채로 넘어가버린다는 것...ㅠ
그리고 AI 라이브챗의 경우 모든 문장을 복습하는 게 아니라 내가 선택한 문장을 3개 정도만 나중에 복습시켜 준다는 점이다 그래서 전체 복습하고 싶으면 복습칸 가서 화면 그냥 보기만 해야 댐 그냥 시스템에서 다 반복 복습하게 해 줘요 보고 있니 플랭
하지만 이렇게 다양한 챌린지를 열어 계속해서 학습할 수 있게 동기 부여를 해준다는 점이 마음에 들기도 하고
또 내 스피킹 레벨이 쫌쫌따리로 계속 올라가는 걸 보는 재미도 있다 나는 지금 일상적인 주제의 대화를 영어로 할 수 있는 정도에 해당한다 다만 이제 정말정말 기초적인 일상 주제만 가능한,,,ㅋ (참고로 저는 토익 스피킹 IH 150을 겨우 받은 인간입니다^^)
내 스피킹 레벨에서 간단한 분석도 해줘서 재밌음 저는 아직 9단어 이상의 긴 문장은 구사하지 못한다네요ㅠ 누적학습 시간은 다른 이들에 비해 짧다 왜냐 보통은 가볍게로 많이 하거든요
레벨이 800 이상까지 있던데 일단은 +100 해서 650 정도까지 올리는 걸 목표로 또 꾸준히 해서 후기 가져오고자 한다
혼공네트의 마지막 주차 공부 시간입니다. 도서관 반납을 위해 오늘도 달려보게씀니다ㅏㅏ 근데 바깥에 눈이 진짜 많이 오네요 입춘도 지났는데 지구야 이것 뭐예요...? 우리가 잘못했어,,, 미안해,,, ㅠㅠ
아무튼 마지막 6주 차에 할 공부는요
<목차> Chapter 1. 컴퓨터 네트워크 시작하기 Chapter 2. 물리 계층과 데이터 링크 계층 Chapter 3. 네트워크 계층 Chapter 4. 전송 계층 Chapter 5. 응용 계층 Chapter 6. 실습으로 복습하는 네트워크 Chapter 7. 네트워크 심화
네트워크 패킷을 직접 보면서 지금까지 배운 내용을 복습하고(챕터 6), 네트워크의 중요 요소 중 하나인 안정성을 알아보는(챕터 7) 시간을 가진대요
혼공단 마지막 숙제는요 와이어샤크란 프로그램을 이용해 실제 TCP/UDP 패킷을 확인하기입니다
지난 내용 복습하기
어제 또 많은 걸 공부했으니 천천히 복습부터 시작 너무 몰아서 공부해서 과부하 오는 거 아닌가 몰라 ^^;;
계층명
지난 핵심
다 합쳐서 복습하기
응용
DNS (계층적, 레코드, 재귀/반복적 질의), HTTP 특징, 캐시, 쿠키
- OSI 참조 모델 최상단에 있는 계층 - 사용자 및 사용자들이 이용하는 응용 프로그램과 가장 밀접한 계층
(DNS) 호스트 IP 주소와 대응되는 문자열 형태의 호스트 특정 정보인 도메인 네임을 관리하기 위한 체계 - 도메인 네임과 마찬가지로 계층적이며, 루트 > TLD(최상위) > 책임 > 로컬 네임 서버 순 - 도메인 네임으로 IP를 알아내는 과정을 리졸빙이라 하고, 재귀적 질의와 반복적 질의 방식이 있음 >> 재귀적 질의 : 로컬 네임 서버는 루트 네임 서버에게 1번만 물어보고, 루트 네임 서버부터 책임 네임 서버까지 순차적으로 내려가며 질의를 반복하고 응답 결과를 역순으로 전달받는 방식 >> 반복적 질의 : 로컬 네임 서버가 루트~책임 네임 서버까지 직접 질의해서 응답 결과를 얻는 방식 - 네임 서버는 DNS 레코드 정보를 저장하고 관리함. 레코드 타입에는 A, AAAA, CNAME, NS, MX 등
(HTTP) 요청-응답 기반 + 미디어 독립적 + 스테이트리스 + 지속 연결형 응용 계층 프로토콜 - HTTP 메세지 구조는 시작 라인, 필드라인, 메시지 본문으로 구성 - HTTP 메서드에는 GET, POST, HEAD, PUT, PATCH, DELETE 등 - HTTP 상태 코드는 요청에 대한 결과를 나타내는 세자리 정수로, 백의 자리를 기준으로 유형 구분 >> 200 OK, 201 Created, 301 Moved Permanently, 308 Permanent Redirect, 400 Bad Request, 403 Forbidden, 404 Not Found, 500 Internal Server Error, 502 Bad Gateway, 503 Service unavailable
(인증 Authentication) 자신이 누구인지 증명하는 것. 주체 신원 검증을 위한 사용 증명 활동 LIKE 암호 (인가=권한 부여 Authorization) 인증된 주체에게 작업을 허용하는 것 LIKE 접근제어목록, 보안등급
(캐시 Cache) 불필요한 대역폭 낭비와 응답 지연 방지를 위해 정보 사본을 임시로 저장하는 기술 또는 저장된 데이터 자체. 유효기간을 설정하고, 유효기간 만료시 캐시의 신선도를 재검사함 (쿠키 Cookie) 서버에서 생성되어 클라이언트측에 저장되는 데이터로 스테이트리스 프로토콜인 HTTP의 특성을 보완, 두 개의 요청이 같은 클라이언트에서 온 것인지 확인하는 세션 인증 등에 활용
전송
연결/신뢰형 통신 프로토콜 TCP (연결 수립 및 종료 방식인 핸드셰이크 +오류/흐름/혼잡 제어)
비연결/비신뢰형 통신 프로토콜 UDP (속도 빠른 실시간성 서비스)
-연결형 통신, 신뢰성 있고 안전성 있는 통신을 해야 할 때 필요한 계층 - OSI 7계층 중 하위 3계층과 상위 3계층간 인터페이스 담당 - 재전송을 통한 오류 제어, 흐름 제어 혼잡 제어 수행 - 전송 단위는 세그먼트 - 장비는 게이트웨이 - 관련 프로토콜로는 TCP, UDP
(포트)특정 애플리케이션까지 패킷을 전달하기 위해 사용하는 식별정보 - 16비트(2바이트)로 표현하며, 번호 범위에 따라 잘 알려진 포트(0~1023), 등록된 포트(1024~49151), 동적 포트(49152~65535)로 구분함 - 전송 계층에서는 패킷 내 송/수신지 포트 번호를 통해 송/수신지 호스트의 애플리케이션을 식별함 - NAPT는 포트를 활용해 하나의 공인 IP 주소를 여러 사설 IP 주소가 공유할 수 있도록 하여, 공인 IP 주소 수 부족 문제를 개선하는 NAT 기술
(TCP) 신뢰성, 연결지향적, TCP 상태 사용. 오류/흐름/혼잡 제어 - 가상회선 방식으로, 패킷 전송 순서를 보장하고 수신 여부도 확인함 >> TCP 연결 수립은 3 웨이 핸드셰이크, 연결 종료는 4 웨이 핸드셰이크를 사용함 - 데이터 신뢰성이 높은 대신 속도가 느림 -(오류 제어)데이터 오류/유실 발생시재전송을 통해 신뢰성을 보장하려는 방식 중복된 ACK 수신 혹은 타임아웃 발생시 재전송을 하는데, Stop-and-Wait, Go-Back-N, Selective Repeat ARQ가 가장 대표적인 방식 -(흐름 제어)데이터송수신측간 데이터 처리 속도 차이로 인한 데이터 손실을 방지하려는 방식으로, 수신측이 주체. 파이프라이닝과 슬라이딩 윈도우 활용 -(혼잡 제어) 데이터 송신 측의 전달 속도와 네트워크의 속도 차이로 인한 데이터 손실을 방지하려는 목적. 송신 측이 주체. 혼잡 윈도우를 통해 네트워크 혼잡도를 판단, 혼잡한 정도에 따라 전송량을 유동적으로 조절하는 방식 대표적인 혼잡 제어 알고리즘으로 AIMD, 느린 시작, 혼잡 회피, 빠른 회복 등이 있으며, 네트워크 상황에 따라 각 방식을 함께 이어서 사용
(UDP) 비신뢰성, 비연결성, 스테이트리스 프로토콜 - 데이터그램 패킷 교환 방식으로, 패킷 순서 보장이나 수신 여부 확인을 하지 않음 - 데이터 신뢰성이 낮은 대신 속도가 빨라 실시간 서비스에 적합
네트워크
인터넷 프로토콜 IP IP 주소(IPv4, IPv6) ARP(IP to MAC) 네트워크 클래스 NAT(공인/사설IP) DHCP(IP 동적할당) 라우팅 프로토콜 (내부 RIP&OSPF, 외부 BGP)
- 메시지를 다른 네트워크에 속한 수신지까지 전달하는 계층 =네트워크 간 통신계층 - IP는 데이터그램 기반비신뢰성, 비연결성 서비스로, IP 단편화(패킷의 분해 및 조립), IP 주소 지정, 경로 선택 기능을 가짐 - 개방 시스템 들 간 네트워크 연결 설정/유지/관리 기능, 데이터의 교환/중계 기능, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행함 - 전송 단위는 패킷 - 장비로는라우터 - 관련 프로토콜로는 IP, ICMP, IGMP, ARP, RARP 등
-IPv4는 4바이트(32비트)+10진수 표현, 클래스 단위로 비순차적으로 할당함. 보안 기능이 없으며, 패킷 크기에 제한(64바이트)이 있음. 유니캐스트/브로드캐스트/멀티캐스트 방식을 사용함 -IPv6는 16바이트(128비트)+16진수 표현, 네트워크/단말 순서로 순차적으로 할당함. 확장 헤더를 사용해 인증/보안 기능을 포함하며, 패킷 크기에 제한이 없음.유니캐스트/멀티캐스트/애니캐스트 방식을 사용함
- 하나의 IP 주소는 네트워크 주소와 호스트 주소로 구성된 - (클래스 풀 주소 체계) 네트워크 크기에 따라 IP 주소를 분류하는 걸 클래스라 함. 클래스는 A~E까지 5개 존재. 클래스 풀 주소는 네트워크 크기가 고정이라는 한계가 존재함 - (클래스리스 주소 체계) 네트워크 주소는 1로, 호스트 주소는 0으로 표기하여 임의로 나누는 방식을 서브넷 마스크라 함. IP 주소와 서브넷 마스크를 비트 AND 연산하면 네트워크 주소가 나온다. 서브넷 마스크는 10진수로 표기하거나, IP 주소/서브넷 마스크 상 1의 개수 형식으로 표현하는 CIDR 표기법을 사용함
- ARP 프로토콜은 "동일 네트워크 내에서" IP 주소를 통해 MAC 주소를 알아내는 과정. ARP 요청(브로드캐스트) > ARP 응답(유니캐스트) > ARP 테이블 갱신 순으로 동작한다. - NAT는 공인 IP와 사설 IP를 상호 변환해주는 기술 - DHCP는 네트워크 안의 호스트들에게 IP와 DNS 서버, 서브넷 마스크 주소를 동적으로 할당하는 프로토콜. DHCP 할당은 DISCOVER, OFFER, REQUEST, ACK 4단계로 구성됨(모두 브로드캐스트).
- 라우팅 프로토콜은 라우터끼리 자신들의 정보를 교환하며 패킷이 이동할 최적의 경로를 찾고자 사용. AS 내부에서 수행되면 IGP로 RIP와 OSPF가 있고, 외부에서 수행되면 EGP로 BGP가 있음 - IGP는 거리 벡터를 사용하는 RIP와 링크 상태를 사용하는 OSPF/IS-IS로 나뉨
데이터 링크
NIC 스위치 (전이중 통신+VLAN)
- 네트워크 내 주변장치 간 정보를 올바르게 주고받기 위한 계층 - MAC 주소 체계를 통해 네트워크 내 송수신지를 특정 - 물리적으로 연결된 인접한 개방 시스템들 간 신뢰/효율적 정보 전송을 위해 시스템 간 연결 설정과 유지 및 종료 담당 - 오류 검출 및 회복을 위한 오류 제어, 송수신측 속도 차이 해결을 위한 흐름 제어, 프레임 순서적 전송을 위한 순서 제어 기능을 가짐 - 전송 단위인 프레임에 물리적 주소를 부여함 - 장비로는 랜카드, 브리지, 스위치 등 - 관련 프로토콜로는 HDLC, LAPB, LLC, MAC, LAPD, PPP, 이더넷 등
- 스위치는 전이중 통신을 한다. MAC 주소 학습과 테이블을 이용해, 특정 MAC 주소를 가진 호스트에만 프레임을 전달할 수 있다. MAC 주소 학습은 플러딩, 포워딩과 필터링, 에이징을 통해 이루어진다. - 스위치는 또한 가상의 LAN을 만드는 VLAN 기능을 지원한다.
물리
트위스티드 페어 케이블 광섬유 케이블 허브(반이중 통신+CSMA/CD)
- OSI 모델 최하단 계층 - 0과 1로 표현되는 비트 신호를 주고 받음 (전송단위가 Bit) - 통신 케이블로 데이터를 전송하는 물리적 장비에 필요한 기계/전기/기능/절차적 특성에 대한 규칙을 정의 - 장비로는 통신 케이블, 리피터, 허브 등 - 관련 프로토콜로는 RS-232C, X.21 등 - 허브는 반이중 통신을 해서 무전기처럼 송수신을 번갈아 가면서 한다. 다른 호스트가 기다리지 않고 신호를 보낼시 충돌 위험이 있는데 이를 방지하는 프로토콜이 CSMA/CD이다. Carrier Sense(캐리어를 감지하고) Multiple Access(다중 접근시에) Collision Detection(충돌을 검출)한다.
그럼 본격적으로 마지막 공부 시작해 볼게요
와이어샤크 활용 패킷 관찰
패킷 캡처 프로그램은 네트워크에서 송수신되는 패킷을 모니터링하고 분석할 수 있는 프로그램으로, 대표적으로 와이어샤크(Wireshark)라는 프로그램이 있다. 와이어샤크는 패킷 캡처, 패킷 필터링과 같이 패킷 내용을 분석하는데 필요한 기능을 제공한다 (다운로드는 여기서)
화면 보니 예전에 보안 회사에서 인턴 하던 거 갑자기 생각난다... 거기서 악성코드 분석부터 시작해서 웹 해킹 이런 거 조금 맛봤는데 악성코드 분석은 2진수 보면서 패턴 찾기 보고 바로 나의 길이 아니다 했다죠 내 동기는 재밌다고 맨날 보던데... 그게 억덕케 재밌는 건데... 신기...
아무튼 와이어 샤크는 직접 써보면 되는 거라 프로그램 소개만 하고 넘어갑니다 어떤 패킷을 봐야 할지 모르겠다면 저자 깃헙에 제공되는 학습용 예시 파일을 활용하세요.
안정성을 위한 기술 : 가용성, 이중화/다중화, 로드 밸런싱
# 가용성 availability
안전성은 특정 기능을 언제든 균일한 성능으로 수행할 수 있는 특성을 말한다. 웹 서버가 안정적이라면 언제든 응답 메시지를 제공할 수 있다. 안정성을 수치화하여, 안정성의 정도를 나타내는 용어가 가용성이다. 가용성이란 컴퓨터 시스템이 특정 기능을 실제로 수행할 수 있는 시간의 비율을 의미한다. 수식으로 나타내면 가용성 = 업타임 / (업타임+다운타임)이라고 표현한다. 이 값이 크면 전체 사용 시간 중 대부분이 사용가능하다는 의미로, 가용성이 높다고 표현한다. 가용성이 높은 성질은 고가용성(HA, High Availability)로 표현하기도 한다.
가용성을 높이려면 다운타임을 낮추어야 한다. 다운타임은 과도한 트래픽, 예기치 못한 소프트웨어상 오류, 하드웨어 장애, 혹은 보안 공격이나 자연재해 등 다양한 원인으로 발생한다. 현실적으로 문제 발생의 모든 원인을 찾아내 차단하기는 어렵기에, 대신 문제가 발생하더라도 계속 동작할 수 있도록 설계하는 전략을 취한다. 문제가 발생하더라도 계속 기능할 수 있는 능력을 결함 감내 fault tolerance라 한다.
# 이중화와 다중화
결함을 감내하여 가용성을 높이기 위한 가장 기본 방법은 이중화이다. 무언가를 이중으로 두어 예비(백업)을 마련하는 방법이다. 이중화할 수 있는 대상은 '문제가 발생할 경우 시스템 전체가 중단될 수 있는 대상'인 단일 장애점(SPOF, Single Point of Failure)으로, 서버부터 라우터, 데이터베이스까지 거의 무엇이든 될 수 있다.
이중화 구성에는 크게 액티브/스탠바이 active-standby(passive)와 액티브/액티브 active-active가 있다. 액티브는 가동 상태를 의미하며, 스탠바이는 액티브의 백업으로 대기하는 상태를 의미한다. 참고로 액티브 시스템에 문제가 생겼을 때 예비 스탠바이로 자동 전환되는 기능을 페일오버 failover 라 한다.
액티브/스탠바이 active-standby
액티브/액티브 active-active
한 시스템만 가동하고, 다른 시스템은 스탠바이(백업 용도로 대기)
안전한 구성이나 성능상 이점은 없음
두 시스템 모두 가동 상태로 두는 구성 방식
부하 분산 및 성능상 이점이 있으나, 한 시스템 문제 발생시 다른 시스템에 부하 발생 가능성 높아짐
[스탠바이 종류 3가지] 1) 핫(Hot) : 스탠바이 가동 후 즉시 이용 가능 2) 웜(Warm) : 스탠바이 가동 후 이용까지 약간의 준비가 필요한 구성 3) 콜드(Cold) : 스탠바이를 정지시켜 두는 구성
출처 : 티스토리 블로그 akku-dev님
만약 장비를 2개가 아니라 3개 이상으로 두어 관리하면 더욱 안정적인데, 이를 다중화라고 한다. 이중화/다중화 사례로 티밍 teaming과 본딩 bonding이 있다. 전자는 윈도우, 후자는 리눅스에서 주로 사용하는 용어인데, 여러 개의 네트워크 인터페이스 NIC를 이중화/다중화하여 마치 더 뛰어나고 안정적인 성능을 보유한 하나의 인터페이스처럼 보이게 하는 기술이다.
# 로드 밸런싱 load balancing
서버 다중화만으로 가용성 문제가 모두 해결되지는 않는다. 서버의 가용성에 큰 영향을 끼치는 요소인 트래픽도 고려해야 한다. 서버에 과도한 트래픽이 몰리면 다양한 문제가 발생할 수 있기 때문이다. 그래서 트래픽의 고른 분배를 위해 로드 밸런싱 기술을 사용한다. 부하를 의미하는 로드 load와 균형 유지를 나타내는 밸런싱 balancing이 합쳐진 단어이다. 로드 밸런싱은 로드 밸런서에 의해 수행된다. 로드 밸런서는 L4/L7 스위치와 같이 네트워크 장비일 수도 있고, HAProxy, Envoy 또는 Nginx와 같이 소프트웨어일 수도 있다.
출처 : https://www.cloudv.kr/etc/lb.html
# HTTP의 중간 서버, 프록시와 게이트웨이
클라이언트와 서버 사이에는 수없이 많은 서버들이 존재한다. 그래서 클라이언트가 최종적으로 메시지를 주고받는 대상을 오리진 서버라고 하기도 한다. 클라이언트와 오리진 서버 사이에 놓인 수많은 중간 서버들을 프록시와 게이트웨이라 한다.
프록시 proxy는 클라이언트가 선택한 메시지 전달 대리자로 포워드 프록시라 하기도 한다. 프록시는 주로 캐시 저장, 클라이언트 암호화 및 접근 제한 등의 기능을 제공하며, 일반적으로 클라이언트와 더 가까이에 위치해 있다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함
게이트웨이 gateway는 일반적으로 네트워크 간 통신을 가능하게 하는 입구 역할을 하는 소프트웨어 또는 하드웨어라는 의미를 가진다. 하지만 HTTP 중간 서버라는 맥락에서는 아웃바운드 연결에 대해 오리진 서버 역할을 하지만, 수신된 요청을 변환하여 다른 인바운드 서버들로 전달하는 중개자 역할을 한다. 여기서 아웃바운드는 클라이언트를 향하는 메시지, 인바운드는 오리진 서버를 향하는 메시지를 의미한다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함
안전성을 위한 기술 : 대칭/공개 키 암호화, SSL/TLS
# 대칭 키와 공개 키 암호화 방식
대칭 키 암호화 symmetric key cryptography 방식은 암호화와 복호화에 동일한 키를 사용한다. 메시지를 암호화하고 복호화하는 데 사용하는 키가 동일하다. 키가 중요하기 때문에 유출되면 안 되고, 키 또한 안전하게 전달해야 한다는 단점이 존재한다.
출처 : www.sinsiway.com/kr/pr/blog/view/412/page/9
키를 안전하게 전달할 방법을 찾을 바엔 그 방법으로 메시지를 보내는 게 맞지 않나란 생각에서 등장한 것이 공개키 암호화 public key crytography 방식이다. 비대칭키 암호화 asymmetric key cryptography 방식이라고 부르기도 한다. 암호화와 복호화를 위한 키가 각각 다른 방식이고, 이 한 쌍의 키를 각각 공개 키와 개인 키라고 부른다. 공개 키로는 개인 키를 유추할 수 없고, 그 반대도 불가하다. 공개 키로는 암호화를 하고 개인 키로 복호화하는 방식이라, 공개 키는 누구에게든 공개해도 무방하다.
출처 : www.sinsiway.com/kr/pr/blog/view/412/page/9
대칭 키는 키를 안전하게 전송하기 어렵지만, 부하가 적어 암/복호화가 빠르다. 반대로 공개 키 암호화는 암/복호화가 느린 대신 키를 안전하게 공유할 수 있다. 이러한 장단점을 고려해 두 방식을 함께 사용하기도 한다. 대칭 키를 상대에게 안전하게 전달하고자 공개 키로 암호화하고, 개인 키로는 암호화된 대칭 키를 복호화 하는 것이다. 이렇게 하면 대칭 키를 안전하게 공유할 수 있고, 대칭 키로 원하는 내용을 빠르게 암/복호화도 할 수 있게 된다. 이렇게 사용하는 방식을 세션 키 session key라고 한다.
출처 : 티스토리 블로그 skogkatt님
⭐️⭐️ 시험에 진짜 맨날 나오는 부분이라 표로 정리하고 넘어가 보자 ⭐️⭐️
내용
대칭 키
공개 키(비대칭 키)
키의 관계
암호화 키 = 복호화 키
암호화 키 != 복호화 키
암호키 공개여부
비공개
공개
복호키 공개여부
비공개
비공개
키의 개수
n(n-1)/2개
2n개
1인당 키
n-1개
n개
암/복호화 속도
빠름 + 효율적
느림 + 비효율적
인증
키 공유자
누구나 가능
장점
키의 길이가 짧음 암/복호화 속도가 빠름
키 분배가 용이함 사용자 수에 따라 관리할 키 개수가 적은 편 여러 분야에 활용 가능
단점
사용자 수에 따라 관리할 키 개수가 많은 편 키 변화의 빈도가 잦음
키의 길이가 김 암/복호화 속도가 느림
종류
DES, AES, SEED, ARIA, Twofish
RSA(Rivest, Shamir, Adleman), ElGamal, 타원 곡선 암호, 배낭 암호
파란색으로 표시한 건 안 외워져서 내 나름대로 외우는 방법이다^^ ES가 들어가거나 앞뒤가 A로 끝나면 대칭 키,,,ㅋ
# 인증서와 디지털 서명
네트워크에서 말하는 인증서는 보통 공개 키 인증서를 의미하는데, 공개 키와 공개 키의 유효성을 입증하기 위한 전자문서를 가리킨다. 이러한 인증서는 인증 기관(CA, certification Authority)라는 제3의 기관에서 발급한다. 인증 기관은 인증서의 발급, 검증, 저장과 같은 역할을 수행하는 공인기관으로, 대표적으로 IdenTrust, DigiCert, GlobalSign 등이 있다. CA가 발급한 인증서에는, 공개 키 인증서가 진짜라는 보증을 담은 서명 값 signature가 있다. 클라이언트는 이 서명 값을 바탕으로 인증서를 검증할 수 있다.
서명 값은 1) 인증서 내용에 대한 해시 값(지문 fingerprint)을, 2) CA의 개인 키로 암호화하는 방식으로 만들어진다. CA는 이렇게 얻어낸 정보를 서명 값으로 삼아 클라이언트에게 인증서와 함께 전송한다.
클라이언트는 인증서 검증을 위해 1) 서명 값과 인증서를 분리하고, 2) 서명 값을 CA의 공개키로 복호화해 해시 값을 얻는다. 클라이언트는 이렇게 얻은 해시값을, 인증서 데이터에 대해 구한 해시 값과 비교하는 절차를 거친다. 이렇게 개인 키로 암호화된 메시지를 공개 키로 복호화하여 신원을 증명하는 절차를 디지털 서명 digital signature 이라 부른다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함 (좌 CA 암호화, 우 클라이언트 복호화)
# HTTPS: SSL과 TLS
지금까지 공부한 대칭/공개키 암호화 방식을 기반으로 동작하는 SSL(Secure Sockets Layer)와 TLS(Transport Layer Security)라는 프로토콜이 있다. 둘 다 인증과 암호화를 수행하는 프로토콜로, TLS는 SSL을 계승한 프로토콜이다.
SSL/TLS를 사용하는 대표적인 프로토콜이 HTTPS(HTTP over TLS)이다. HTTPS는 HTTP 메시지의 안전한 송수신을 위해 개발되었다. 오늘날 주로 사용되는 TLS 1.3을 기반으로 HTTPS가 어떻게 동작하는지 확인해 보자. HTTPS 메시지는 크게 아래와 같은 세 단계를 거쳐 송수신한다.
1) TCP 쓰리 웨이 핸드셰이크 2) TLS 핸드셰이크 : 암호화 통신을 위한 키를 교환함 + 인증서 송수신과 검증이 이루어짐 - ClientHello : (클라이언트 >> 서버) 암호화된 통신을 위해 서로 합의할 정보들을 제시하는 메시지. 지원되는 TLS 버전, 사용 가능한 암호화 방식과 해시 함수(암호 스위트 cipher suite), 클라이언트 난수 등이 포함되어 있음 - ServerHello : (서버 >> 클라이언트) 제시된 정보들을 선택하는 메시지. 선택된 TLS 버전, 암호 스위트 정보, 서버 난수 등이 포함 >> 두 메시지를 주고받고 나면 암호화된 통신을 위해 사전 협의해야 할 정보들이 모두 결정됨 3) 암호화된 메시지 송수신
출처 : https://brunch.co.kr/@growthminder/79
무선 네트워크
# 전파와 주파수, 와이파이와 802.11
전파 radio wave는 약 3kHz부터 3THz 사이의 진동수를 갖는 전자기파이다. 수많은 무선 통신 기기가 전자기파를 이용하여 통신하고, 이를 위해 통신에 사용되는 전파는 주파수 대역이 미리 정해져 있다. 아래와 같이 분배도표가 있는데 신기해서 가져와 봤다...!
출처 : 한국전파진흥협회 https://www.spectrum.or.kr/
무선 통신 네트워크는 IEEE 802.11로 표준화되어 있고, 802.11 뒤의 알파벳으로 다양한 규격을 표현한다. 그리고 IEEE 802.11 표준은 대부분 2.4 또는 5 GHz 대역을 사용한다. 와이파이 선택할 때 2.4G나 5G가 자주 보이는 건 이 때문이라고(참고로 5G가 속도는 빠르지만 장애물이 많은 환경에는 부적합하다). 버전에 따라 주파수뿐만 아니라 전송 속도, 대역폭, 전송 가능 거리, 변조 방식 등이 다양하게 바뀐다.
2주 차에 IEEE 802 표준 정리했던 거 기억나서 다시 읽어볼 겸 가져와봤다.
와이파이 Wi-Fi는 IEEE 802.11 표준을 따르는 무선 LAN 기술을 가리키는 말로도 많이 사용되지만, 본래는 와이파이 얼라이언스라는 브랜드 네임이다. 그래서 와이파이는 일종의 인증 마크 역할을 한다. 아래와 같이 인증 마크가 붙어 있다면, 그 제품은 특정 IEEE 802.11 규격을 지켰기에 타 제품과도 호환된다는 점을 알 수 있는 것이다.
출처 : https://www.wi-fi.org/ko/certification
마지막으로 무선 네트워크를 생성하기 위해서는 무선 액세스 포인트(AP)라는 네트워크 장비가 필요하다. 우리가 흔히 공유기라고 부르는 장비다. 무선 LAN의 기기들은 AP를 경유해 인터넷에 접속하거나 서로 메시지를 주고받을 수 있다. 이렇게 AP를 경유하여 통신이 이루어지는 무선 네트워크 통신 방식을 인프라스트럭처 모드라고 한다. 무선 네트워크를 이루는 AP와 여러 장치들의 집합을 서비스 셋이라 하는데, 여러 서비스 셋을 구분할 때 서비스 셋 식별자(SSID)를 사용한다. 무선 네트워크를 지칭하는 고유한 이름인데, 보통 우리가 접하는 와이파이 이름에 해당한다.
📚 기본 숙제
# (p379) 확인문제 1번 "다음은 호스트 A와 B 간의 쓰리 웨이 핸드셰이크 과정에서 호스트 A가 호스트 B에게 전송한 첫 번째 SYN 세그먼트의 일부입니다. 쓰리 웨이 핸드셰이크상에서 호스트 B가 호스트 A에게 전송할 다음 세그먼트의 ACK NUM(raw)는 무엇일까요?" >> 문제에 적힌 SEQ NUM(raw)에 1을 더한 값이 답이다. 즉 3588415412+1이 답이다.
# (p407) 확인문제 2번 "다음 그림은 두 호스트가 TLS 1.3 핸드셰이크를 수행하는 과정을 나타낸 그림의 일부입니다. 괄호 안에 들어갈 TLS 관련 메시지로 알맞은 말을 골라 보세요" >> 답은 3번 ServerHello이다. 클라이언트가 암호화 통신을 위해 합의해야 할 내용들을 ClientHello에 담아 보냈기에, 서버는 그중에서 원하는 걸 선택해 ServerHello에 담아 보낸다.
🦈 추가 숙제 : 와이어샤크로 TCP/UDP 패킷 확인해 보기
순서대로 TCP와 UDP로 필터링을 걸어서 조회해 본 결과이다. 왼쪽은 TCP라서 FIN이나 ACK 같은 글자도 보이고, SEQ NUM이나 ACK NUM도 볼 수 있다. 반대로 오른쪽은 UDP라서 더 간단하고, 송/수신지 포트나 체크썸 같은 값들도 볼 수 있다.
이렇게 해서 진짜 찐으로 혼공단 13기 혼공네트를 마칩니다. 할 수 있을까 걱정했는데 나름 알차게, 그리고 벼락치기로^^7 성공
지난해 너무 놀고먹고 한 죄를 청산하고자 의지를 체면과 돈으로 사서 겨우겨우 공부하고 있는데요 (참여 예고까지 한 혼공단 완주는 내 블로그 체면이 되)
2-3월에 할 일 디지게 많아요^ㅁ^ 너무 무리했나바요... 차근차근 정리+계획해 보려다가 때려치우고 걍 일단 하자!! 마인드로 가봅니다
우선 혼공네트 책을 도서관에 가져다 드려야 할 날이 임박하여 일정표와 달리 예습하는 콘텐츠로 준비했어요
벌써 5주 차인 오늘 할 공부는요
<목차> Chapter 1. 컴퓨터 네트워크 시작하기 Chapter 2. 물리 계층과 데이터 링크 계층 Chapter 3. 네트워크 계층 Chapter 4. 전송 계층 Chapter 5. 응용 계층 Chapter 6. 실습으로 복습하는 네트워크 Chapter 7. 네트워크 심화
네트워크 모델의 최상단응용 계층이라죠 OSI 7 모델 기준으로는 응용/표현/세션 계층이었는데요 이 구조 기억하는 새럼~?!
출처 : velog @funnysunny08님
혼공단 숙제는요 HTTP 요청 메시지 확인해 보는 거라죠
지난 내용 복습하기
빠지면 서운한 복습부터 가보겠습니다 포스팅한 지 이틀 밖에 안 지났는데 벌써 기억 안나고요 ㅎ
계층명
지난 주 핵심
다 합쳐서 복습하기
전송
연결/신뢰형 통신 프로토콜 TCP (연결 수립 및 종료 방식인 핸드셰이크 +오류/흐름/혼잡 제어)
비연결/비신뢰형 통신 프로토콜 UDP (속도 빠른 실시간성 서비스)
-연결형 통신, 신뢰성 있고 안전성 있는 통신을 해야 할 때 필요한 계층 - OSI 7계층 중 하위 3계층과 상위 3계층간 인터페이스 담당 - 재전송을 통한 오류 제어, 흐름 제어 혼잡 제어 수행 - 전송 단위는 세그먼트 - 장비는 게이트웨이 - 관련 프로토콜로는 TCP, UDP
(포트) 특정 애플리케이션까지 패킷을 전달하기 위해 사용하는 식별정보 - 16비트(2바이트)로 표현하며, 번호 범위에 따라 잘 알려진 포트(0~1023), 등록된 포트(1024~49151), 동적 포트(49152~65535)로 구분함 - 전송 계층에서는 패킷 내 송/수신지 포트 번호를 통해 송/수신지 호스트의 애플리케이션을 식별함 - NAPT는 포트를 활용해 하나의 공인 IP 주소를 여러 사설 IP 주소가 공유할 수 있도록 하여, 공인 IP 주소 수 부족 문제를 개선하는 NAT 기술
(TCP) 신뢰성, 연결지향적, TCP 상태 사용. 오류/흐름/혼잡 제어 - 가상회선 방식으로, 패킷 전송 순서를 보장하고 수신 여부도 확인함 >> TCP 연결 수립은 3 웨이 핸드셰이크, 연결 종료는 4 웨이 핸드셰이크를 사용함 - 데이터 신뢰성이 높은 대신 속도가 느림 - (오류 제어) 데이터 오류/유실 발생시 재전송을 통해 신뢰성을 보장하려는 방식 중복된 ACK 수신 혹은 타임아웃 발생시 재전송을 하는데, Stop-and-Wait, Go-Back-N, Selective Repeat ARQ가 가장 대표적인 방식 - (흐름 제어) 데이터 송수신측간 데이터 처리 속도 차이로 인한 데이터 손실을 방지하려는 방식으로, 수신측이 주체. 파이프라이닝과 슬라이딩 윈도우 활용 - (혼잡 제어) 데이터 송신 측의 전달 속도와 네트워크의 속도 차이로 인한 데이터 손실을 방지하려는 목적. 송신 측이 주체. 혼잡 윈도우를 통해 네트워크 혼잡도를 판단, 혼잡한 정도에 따라 전송량을 유동적으로 조절하는 방식 대표적인 혼잡 제어 알고리즘으로 AIMD, 느린 시작, 혼잡 회피, 빠른 회복 등이 있으며, 네트워크 상황에 따라 각 방식을 함께 이어서 사용
(UDP) 비신뢰성, 비연결성, 스테이트리스 프로토콜 - 데이터그램 패킷 교환 방식으로, 패킷 순서 보장이나 수신 여부 확인을 하지 않음 - 데이터 신뢰성이 낮은 대신 속도가 빨라 실시간 서비스에 적합
네트워크
인터넷 프로토콜 IP IP 주소(IPv4, IPv6) ARP(IP to MAC) 네트워크 클래스 NAT(공인/사설IP) DHCP(IP 동적할당) 라우팅 프로토콜 (내부 RIP&OSPF, 외부 BGP)
- 메시지를 다른 네트워크에 속한 수신지까지 전달하는 계층 =네트워크 간 통신계층 - IP는 데이터그램 기반비신뢰성, 비연결성 서비스로, IP 단편화(패킷의 분해 및 조립), IP 주소 지정, 경로 선택 기능을 가짐 - 개방 시스템 들 간 네트워크 연결 설정/유지/관리 기능, 데이터의 교환/중계 기능, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행함 - 전송 단위는 패킷 - 장비로는라우터 - 관련 프로토콜로는 IP, ICMP, IGMP, ARP, RARP 등
-IPv4는 4바이트(32비트)+10진수 표현, 클래스 단위로 비순차적으로 할당함. 보안 기능이 없으며, 패킷 크기에 제한(64바이트)이 있음. 유니캐스트/브로드캐스트/멀티캐스트 방식을 사용함 -IPv6는 16바이트(128비트)+16진수 표현, 네트워크/단말 순서로 순차적으로 할당함. 확장 헤더를 사용해 인증/보안 기능을 포함하며, 패킷 크기에 제한이 없음.유니캐스트/멀티캐스트/애니캐스트 방식을 사용함
- 하나의 IP 주소는 네트워크 주소와 호스트 주소로 구성된 - (클래스 풀 주소 체계) 네트워크 크기에 따라 IP 주소를 분류하는 걸 클래스라 함. 클래스는 A~E까지 5개 존재. 클래스 풀 주소는 네트워크 크기가 고정이라는 한계가 존재함 - (클래스리스 주소 체계) 네트워크 주소는 1로, 호스트 주소는 0으로 표기하여 임의로 나누는 방식을 서브넷 마스크라 함. IP 주소와 서브넷 마스크를 비트 AND 연산하면 네트워크 주소가 나온다. 서브넷 마스크는 10진수로 표기하거나, IP 주소/서브넷 마스크 상 1의 개수 형식으로 표현하는 CIDR 표기법을 사용함
- ARP 프로토콜은 "동일 네트워크 내에서" IP 주소를 통해 MAC 주소를 알아내는 과정. ARP 요청(브로드캐스트) > ARP 응답(유니캐스트) > ARP 테이블 갱신 순으로 동작한다. - NAT는 공인 IP와 사설 IP를 상호 변환해주는 기술 - DHCP는 네트워크 안의 호스트들에게 IP와 DNS 서버, 서브넷 마스크 주소를 동적으로 할당하는 프로토콜. DHCP 할당은 DISCOVER, OFFER, REQUEST, ACK 4단계로 구성됨(모두 브로드캐스트).
- 라우팅 프로토콜은 라우터끼리 자신들의 정보를 교환하며 패킷이 이동할 최적의 경로를 찾고자 사용. AS 내부에서 수행되면 IGP로 RIP와 OSPF가 있고, 외부에서 수행되면 EGP로 BGP가 있음 - IGP는 거리 벡터를 사용하는 RIP와 링크 상태를 사용하는 OSPF/IS-IS로 나뉨
데이터 링크
NIC 스위치 (전이중 통신+VLAN)
- 네트워크 내 주변장치 간 정보를 올바르게 주고받기 위한 계층 - MAC 주소 체계를 통해 네트워크 내 송수신지를 특정 - 물리적으로 연결된 인접한 개방 시스템들 간 신뢰/효율적 정보 전송을 위해 시스템 간 연결 설정과 유지 및 종료 담당 - 오류 검출 및 회복을 위한 오류 제어, 송수신측 속도 차이 해결을 위한 흐름 제어, 프레임 순서적 전송을 위한 순서 제어 기능을 가짐 - 전송 단위인 프레임에 물리적 주소를 부여함 - 장비로는 랜카드, 브리지, 스위치 등 - 관련 프로토콜로는 HDLC, LAPB, LLC, MAC, LAPD, PPP, 이더넷 등
- 스위치는 전이중 통신을 한다. MAC 주소 학습과 테이블을 이용해, 특정 MAC 주소를 가진 호스트에만 프레임을 전달할 수 있다. MAC 주소 학습은 플러딩, 포워딩과 필터링, 에이징을 통해 이루어진다. - 스위치는 또한 가상의 LAN을 만드는 VLAN 기능을 지원한다.
물리
트위스티드 페어 케이블 광섬유 케이블 허브(반이중 통신+CSMA/CD)
- OSI 모델 최하단 계층 - 0과 1로 표현되는 비트 신호를 주고 받음 (전송단위가 Bit) - 통신 케이블로 데이터를 전송하는 물리적 장비에 필요한 기계/전기/기능/절차적 특성에 대한 규칙을 정의 - 장비로는 통신 케이블, 리피터, 허브 등 - 관련 프로토콜로는 RS-232C, X.21 등 - 허브는 반이중 통신을 해서 무전기처럼 송수신을 번갈아 가면서 한다. 다른 호스트가 기다리지 않고 신호를 보낼시 충돌 위험이 있는데 이를 방지하는 프로토콜이 CSMA/CD이다. Carrier Sense(캐리어를 감지하고) Multiple Access(다중 접근시에) Collision Detection(충돌을 검출)한다.
그럼 본격적으로 5주 차 공부 시작해 볼게요
도메인 네임과 (도메인) 네임 서버
우리가 브라우저에 특정 URL을 입력하면 웹 페이지가 뜬다. 뒷단에서 클라이언트와 서버가 요청-응답 메시지를 송수신하고 있기 때문인데, 이때 서버와 클라이언트는 '메시지를 주고받고자 하는 대상'과 '주고받고자 하는 정보'를 알아야 한다.
앞서 공부하면서 '메시지를 주고 받고자 하는 대상'을 알기 위해서는 IP 주소를 사용한다고 배웠다. 하지만 숫자를 언제 다 외워요...? 요즘은 가족 휴대폰 번호도 가끔 헷갈리는 지경인데 말이죠^^ 그래서 우리는 IP 주소 대신 tistory.com과 같은 문자열을 활용해 웹 페이지에 접속하는데요. 이렇게 호스트 IP 주소와 대응되는 문자열 형태의 호스트 특정 정보를 도메인 네임 Domain name이라고 한다.
도메인 네임과 IP 주소는 네임서버 Name server 에서 관리한다. DNS 서버라고도 부르는데, 인터넷 세계의 공용 전화번호부 같은 개념이라고 보면 된다. 아래 그림처럼, 도메인 네임을 네임 서버에 질의하면 해당 도메인 네임에 대한 IP 주소를 알려주는 방식으로 동작한다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함
# 도메인 네임 구조
도메인 네임은 점(.)을 기준으로 계층적으로 분류한다. 최상단에 루트 도메인이 있고, 최상위 도메인, 2단계 도메인, 3단계 도메인 이렇게 순차적으로 내려가는 형태다. 이렇게 생겼는데,
출처 : 한국인터넷정보센터 - 그림으로 보는 도메인 체계
- 루트 도메인 : 점(.)으로 표현되는, (실제) 도메인 네임의 마지막 부분. 일반적으로 생략하고 표기함 - 최상위 도메인(TLD) : 일반적으로 생각하는 도메인 네임의 마지막 부분. com, org, net과 같은 일반TLD와 kr, us, cn과 같은 국가코드TLD로 나뉨 - 2단계 도메인 : 최상위 도메인 하부 도메인으로, www.tistory.com에서 tistory에 해당하는 부분 - 3단계 도메인 : www.tistory.com에서 www에 해당하는 부분 (일반적으로 3~5단계 정도까지만 사용)
www.tistory.com와 같이 도메인 네임을 모두 포함하는 도메인 네임을 전체 주소 도메인 네임(FQDN)이라 한다. 분석해 보면 아래와 같은데,
3단계
2단계
최상위
루트
www
.
tistory
.
com
.
여기서 FQDN의 첫 번째 부분을 호스트 네임이라고 부르기도 한다. 뒷부분이 tistory.com으로 끝나는 수많은 도메인 주소 중에서, www.tistory.com이라는 호스트를 식별할 수 있는 하나밖에 없는 애이기 때문이다. 반대로 lv27.tistory.com, notice.tistory.com으로 끝나는 애들은, 다른 도메인이 포함된 도메인이라 서브 도메인 subdomain 이라 한다.
# 계층적 네임 서버
계층적인 도메인 네임을 효율적으로 관리하기 위해 네임 서버 또한 계층적인 형태를 이룬다. 계층 서버는 전 세계에 널리 퍼져 있는데, 이렇게 분산된 도메인 네임에 대한 관리 체계를 도메인 네임 시스템, DNS라 부른다. DNS는 호스트가 도메인 네임 시스템을 이용할 수 있게 하는 애플리케이션 계층 프로토콜을 지칭하기도 한다. 우리가 IP 주소를 모르는 상태에서 도메인 네임에 대응하는 IP 주소를 알아내는 과정을 '도메인 네임을 풀이resolve한다' 또는 '리졸빙'이라고 표현한다. 이 과정에는 로컬 네임 서버, 루트 네임 서버, TLD 네임 서버, 책임 네임 서버와 같이 다양한 네임 서버들이 필요하다.
- 로컬 네임 서버 : 클라이언트와 맞닿아 있는 네임 서버로, 클라이언트가 도메인 네임을 통해 IP 주소를 알아내고자 할 때 가장 먼저 찾게 되는 네임 서버. 로컬 네임 서버의 주소는 보통 ISP에서 할당해 주지만, 필요하다면 공개 DNS 서버를 이용할 수도 있음(구글 공개 DNS 서버는 8.8.8.8과 8.8.4.4 - 루트 네임 서버 : 루트 도메인을 관장하는 네임 서버로, 로컬 네임 서버의 질의에 대해 TLD 네임 서버의 IP 주소를 반환함 - TLD 네임 서버 : TLD를 관리하는 네임 서버로, 질의에 대해 TLD 하위 도메인 네임을 관리하는 서버 주소를 반환함 - 책임 네임 서버 authoritative name server : 특정 도메인 영역zone을 관리하는 네임 서버로, 자신이 관리하는 도메인 영역의 질의에 대해서는 곧바로 대답이 가능함 = 로컬 네임 서버가 마지막으로 질의하는 네임 서버임
출처 : 컴퓨터 네트워크 하향식 접근 6판 원서
# 도메인 네임을 리졸빙하는 과정 = ⭐️ 재귀적 질의와 반복적 질의 ⭐️
재귀적 질의 recursive query
반복적 질의 iterative query
클라이언트가 로컬 네임 서버에게 도메인 네임을 질의하면, 로컬 네임 서버가 루트 네임 서버에게 질의하고, 루트 네임 서버가 TLD 서버에게 질의하고, TLD 네임 서버가 다음 단계에 질의하는 과정을 반복해 최종 응답 결과를 역순으로 전달받는 방식
클라이언트가 로컬 네임 서버에게 도메인 네임을 질의하면, 로컬 네임 서버는 루트 도메인 서버에게 질의해서 응답받고, 다시 로컬 네임 서버가 TLD 서버에게 질의해서 응답받고, 다시 로컬 네임 서버가 다음 서버에게 질의하는 과정을 반복해 최종 응답 결과를 클라이언트에게 알려주는 방식
로컬 네임 서버는 루트 네임 서버에게 1번만 물어봄 각 서버가 단계별로 내려가면서 물어보고, 자신이 받은 답변을 위로 올려줌
로컬 네임 서버가 루트~책임 서버까지 다 물어봄
근데 매번 이렇게 물어보면 시간도 오래 걸리고 네트워크에 부담이 많이 간다죠. 그래서 기존에 응답받은 결과를 저장해 두었다가, 나중에 같은 질의가 또 오면 대답해주기도 한다. 이를 DNS 캐시라고 하는데요, 저장된 값은 일정 시간(TTL)이 지나고 나면 폐기한다.
# DNS 레코드 타입
네임 서버는 DNS (자원) 레코드라 불리는 정보를 저장하고 관리한다. 도메인 네임을 구입한 뒤에, 웹 사이트에 도메인 네임을 적용시킬 때 사용하게 된다. 도메인 네임이 특정 IP에 대응된다는 사실을 네임 서버에게 알리기 위해 추가하는 작업을 해줘야 하는 것이다. 보통 가비아 같은 곳에서 설정할 수 있다. 아래처럼 생겼는데,
출처 : 가비아 유튜브 내 DNS 레코드 설정 매뉴얼 영상
DNS 레코드에는 이름(호스트)과 값/위치, TTL, 타입이 있다. 각 레코드에는 유형이 정해져 있는데, 자주 접하는 ⭐️레코드 유형은 아래와 같다.
레코드 유형
설명
A (host record)
특정 호스트에 대한 도메인 네임과 IPv4 주소와의 대응 관계 호스트 이름이 정의된 주 영역이라고 보기도 함
AAAA
특정 호스트에 대한 도메인 네임과 IPv6 주소와의 대응 관계
CNAME
호스트 네임에 대한 별칭 지정
NS
특정 호스트의 IP 주소를 찾을 수 있는 네임 서버
MX
해당 도메인과 연동되어 있는 메일 서버
짧게 정리하고 넘어가자면 DNS의 주요 기능은 네임 공간(구조) 생성, 네임 등록 관리, 네임을 IP로 변환 정도라고 보면 될 듯
시험에 자주 나오는 개념들은 이제 ⭐️을 달기로 했다 근데 가비아 홈페이지 보니까 또... 회사 생각나네 시스템 기획/운영 업무하면 도메인 사고 레코드 설정도 하고 그렇답니다^ㅁ^
# 자원을 식별하는 URl
이제까지 서버와 클라이언트가 알아야 하는 정보 중'메시지를 주고받고자 하는 대상'과 관련된 개념을 공부했다. 그렇다면 '주고받고자 하는 정보'는 어떻게 알 수 있을까? 우선 이렇게 네트워크상에서 메시지를 통해 주고받고자 하는 정보를 자원이라고 부른다. 자원은 HTML 파일부터 이미지, 동영상, 텍스트 파일과 같이 정말 다양하다.
네트워크 상에서 자원을 주고받으려면 자원을 식별할 수 있어야 한다. 자원을 식별할 수 있는 정보를 URI, Uniform Resource Identifier라고 부른다. 이름 뜻 그대로 자원을 식별하는 통일된 방식이다. URI에는 위치를 이용해 자원을 식별하는 URL과, 이름을 이용해 자원을 식별하는 URN이 있다.
오늘날 더 많이 쓰이는 방법은 URL, Uniform Resource Locator이다. URL은 보통 이렇게 생겼다.
foo
://
www.example.com:8042
/over/there
?name=hongong
#hanbit
scheme
authority
path
query
fragment
- scheme (자세한 종류는 여기서) 자원에 접근하는 방법을 의미하며, 일반적으로 사용할 프로토콜을 명시함 http를 사용하면 http://, https를 사용하면 https:// - authority 호스트를 특정할 수 있는 정보로 IP 주소나 도메인 네임을 기재함. 콜론(:) 뒤에 포트 번호 붙이기도 함 - path 자원이 위치한 경로 슬래시(/)를 기준으로 계층적으로 표현하며, 최상위 경로도 /로 표현 - query 복잡한 요구를 포함하는 HTTP 요청 메시지를 보낼 때 사용하며, 쿼리 문자열 또는 쿼리 파라미터라 함 물음표(?)로 시작되는 <키=값> 형태로, 앰퍼샌드(&) 연산자를 사용해 연결해서 쓴다 >>> ?key=value&key2=value2 쿼리 문자열은 서버 개발자가 설계하기 나름이라 매우 다양함 - fragment 자원의 한 조각을 가리키기 위한 정보 >> html 페이지 내 특정 부분을 가리키는 등
응용 계층 대표 프로토콜, HTTP
# HTTP의 특성 4가지
(1) 요청-응답 기반 프로토콜 HTTP는 클라이언트-서버 구조 기반의 요청-응답 프로토콜이다. HTTP는 클라이언트와 서버가 서로 HTTP 요청과 응답 메시지를 주고받는 구조로 동작한다.
(2) 미디어 독립적 프로토콜 HTTP는 클라이언트와 서버가 주고 받는 자원의 특성을 제한하지 않는다. 자원의 특성과 무관하게 그저 자원을 주고 받는 수단(인터페이스)의 역할만을 수행한다. HTTP에서 메시지로 주고 받는 자원의 종류를 미디어 타입, 또는 MIME 타입(Multipurpose Internet Mail Extensions Type)이라 한다. 미디어 타입은 일종의 웹 세상의 확장자와 같은 개념으로, <타입/서브타입>으로 구성된다. text/html, image/png 같은 형태다.
(3) 스테이트리스 프로토콜 HTTP는 상태를 유지하지 않는 스테이트리스 프로토콜이다. 서버가 HTTP 요청을 보낸 클라이언트와 관련된 상태를 기억하지 않는다는 의미로, 클라이언트의 모든 HTTP 요청은 독립적 요청으로 간주된다. HTTP 서버는 보통 여러 개가 있고, 많은 클라이언트들과 동시에 상호 작용한다. 이러한 상황에서 클라이언트의 상태 정보를 유지하고 서로 공유하는 일은 쉽지 않다. 그래서 오히려 독립적으로 간주하는 것이 더 효율적이다. 게다가 HTTP의 가장 중요한 설계 목표는 바로 확장성 scalability와 견고성 robustness 이다. 상태를 유지하지 않는 특성으로 인해 필요하다면 언제든 쉽게 서버 추가가 가능하기에 확장성이 높고, 서버 중 하나에 문제가 생겨도 다른 서버로 쉽게 대체가 가능하기에 견고성도 높다고 볼 수 있다.
(4) 지속 연결 프로토콜 최근 대중적으로 사용되는 HTTP 1.1 이상 버전은 지속 연결, 킵 얼라이브 keep-alive라는 기술을 제공한다. 하나의 TCP 연결 상태에서 여러 개의 요청-응답을 주고받을 수 있는 기술이다.
# HTTP 메시지 구조
HTTP 메시지는 시작 라인, 필드 라인, 메시지 본문으로 이루어져 있다. 아래와 같이 생겼는데 내용을 조금 더 자세히 보면
- 시작 라인 start line : HTTP 메시지 종류에 따라 요청/상태 라인으로 구분 >> 요청 라인 = 메서드 (공백) 요청 대상 (공백) HTTP 버전 (줄 바꿈) - 메서드는 클라이언트가 서버의 자원인 요청 대상에 대해 수행할 작업의 종류. GET, POST, PUT 등 - 요청 대상은 HTTP 요청을 보낼 서버의 자원. 보통 쿼리가 포함된 URI 경로가 명시되고는 함 - HTTP 버전은 사용하는 HTTP 버전을 표기. HTTP/1.1과 같이 씀 >> 응답 라인 = HTTP 버전 (공백) 상태 코드 (공백) 이유 구문 (줄 바꿈) - 상태 코드는 요청에 대한 결과를 나타내는 3자리 정수. LIKE 200, 404. 상태 코드를 통해 요청이 어떻게 처리되었는지 알 수 있음 - 이유 구문은 선택 사항으로, 상태 코드에 대한 문자열 형태의 설명임 - 필드 라인 = 헤더 라인 : 0개 이상의 HTTP 헤더가 명시되는 곳 HTTP 헤더는 HTTP 통신에 필요한 부가 정보를 의미하며, 필드 라인에 명시되는 각 HTTP 헤더는 콜론(:)을 기준으로 헤더 이름과 하나 이상의 헤더 값으로 구성됨. 헤더 이름:헤더 값 형태 - 메시지 본문 : HTTP 요청/응답 메시지에 본문이 필요한 경우에 명시
# HTTP 메서드
메서드는 클라이언트가 서버의 자원인 요청 대상에 대해 수행할 작업의 종류라고 하는데요. 종류가 많으니 표로 정리하고 넘어갑니다.
HTTP 메서드명
설명
GET
자원을 습득하기 위한 메서드로, 특정 자원을 조회할 때 사용
HEAD
GET과 동일하나, 헤더만을 응답받는 메서드
POST
서버로 하여금 특정 작업을 처리하게끔 하는 메서드로, 주로 클라이언트가 서버에 새로운 자원을 생성하고자 할 때 사용
PUT
자원을 대체하기 위한 메서드 = 덮어쓰기 요청 자원이 없다면 메세지 본문으로 자원을 새롭게 생성하거나, 존재한다면 메시지 본문으로 자원을 완전히 대체함
PATCH
자원에 대한 부분적 수정을 위한 메서드
DELETE
자원을 삭제하기 위한 메서드
CONNECT
자원에 대한 양방향 연결을 시작하는 메서드
OPTIONS
사용 가능한 메서드 등 통신 옵션을 확인하는 메서드
TRACE
자원에 대한 루프백 테스트를 수행하는 메서드
메서드에 따라 서버가 어떻게 동작할지는 전적으로 개발자가 할 일이다. 그래서 구현하지 않는 메서드가 있을 수도 있다. '어떤 URL로 어떤 요청을 받았을 때 서버가 어떻게 동작할 것인가'는 서버 개발자들의 주된 고민 중 하나이고, 이걸 잘 정리해 둔 문서가 API 문서
# HTTP 상태 코드
상태 코드는 요청에 대한 결과를 나타내는 세 자리 정수로, 백의 자리 수를 기준으로 유형을 구분할 수 있다. 아래 표는 상태 코드 중 일부만 정리한 거다. 실제는 훨씬 많아요. (궁금하면 여기서) 알아두면 좋을 내용이라 책 내용 외에도 더 보려고 검색하다가 족장의 HTTP 상태 코드 전체 요약글도 발견했다죠. 가독성 최고,,, 다들 읽어보세요,,, 츄라이 츄라이
범주
상태코드
이유 구문
설명
100번대 (정보성 상태 코드)
100
Continue
계속 진행
101
Switching Protocols
프로토콜 전환. HTTP 버전을 올려야 할 때 업그레이드 응답 헤더에서 사용
102
Processing
처리 중이니 기달. 서버 처리에 오랜 시간이 걸릴 경우 클라이언트에서 타임 아웃이 발생하지 않도록 이 응답을 보냄
200번대 (성공 상태 코드)
200
OK
서버가 요청을 성공적으로 처리
201
Created
요청이 처리되어 새로운 리소스 생성 완료
202
Accepted
요청 접수되었고 처리는 진행 중
203
Non-Authoritative Info
응답 헤더가 오리지널 서버로부터 제공되지 않음
204
No Content
요청 처리 완료, 클라이언트에게 돌려줄 콘텐츠는 없음
205
Reset Content
처리 성공, 브라우저 화면 리셋해라
300번대 (리다이렉션 상태 코드)
300
Multiple Choices
선택 항목이 여러 개 있음. 서버에서 콘텐츠를 결정하지 못하고 클라이언트에게 복수 개의 링크를 응답할 때 사용
301
Moved Permanently
지정한 리소스가 새로운 URI로 이동. 영구적 리다이렉션. 재요청 메서드 변경 가능 응답 헤더의 Location에 이동할 곳의 새로운 URI를 기재함
302
Found
요청한 리소스를 다른 URI에서 찾음 (사용 미권장)
303
See other
다른 위치로 요청해라. 브라우저의 폼 요청을 POST로 처리하고, 그 결과 화면으로 리다이렉트시킬 때 자주 사용함
304
Not Modified
마지막 요청 이후 요청한 페이지 수정안됨. If-Modified-Since와 같은 조건부 GET 요청에 대한 응답
305
Use Proxy
지정한 리소스 액세스하려면 프록시를 통해야 함
307
Temporary Redirect
임시로 리다이렉션 요청이 필요함
308
Permanent Redirect
지정한 리소스가 새로운 URI로 이동. 영구적 리다이렉션. 재요청 메서드 변경되지 않음
400번대 (클라이언트 에러 상태 코드)
400
Bad Request
요청의 구문이 잘못됨
401
Unauthorized
지정한 리소스에 대한 액세스 권한이 없음
403
Forbidden
지정한 리소스에 대한 액세스가 금지됨. 리소스 존재 자체를 숨기고 싶으면 404로 대체함
404
Not Found
지정한 리소스를 찾을 수 없음
405
Method Not Allowed
요청한 URI가 지정한 메소드를 지원하지 않음. 응답헤더에 URI가 지원하는 메소드 목록을 회신
406
Not Acceptable
클라이언트 Accept 헤더에 지정한 항목에 관해 처리할 수 없음
407
Proxy Authentication Required
클라이언트는 프록시 서버에 인증이 필요함
408
Request Timeout
요청을 기다리다 서버에서 타임아웃함
500번대 (서버 에러 상태 코드)
500
Internal Server Error
서버에 에러가 발생함
501
Not Implemented
요청한 URI의 메소드는 서버에 구현되어 있지 않음
502
Bad Gateway
게이트웨이나 프록시 역할을 하는 서버가 그 뒷단의 서버로부터 잘못된 응답을 수신함 = 중간 서버 통신 오류
503
Service Unavailable
현재 서버에서 서비스를 제공할 수 없음. 서버 과부하 또는 서비스 점검 등 일시적 상태
504
Gateway Timeout
게이트웨이나 프록시 역할을 하는 서버가 그 뒷단의 서버로부터 응답을 기다리다 타임아웃
505
HTTP Ver Not Supported
클라이언트가 요청한 HTTP를 서버가 미지원함
# 추가 학습 : 인증과 인가
인증 Authentication은 자신이 누구인지 증명하는 것이고, 인가(권한 부여) Authorization은 인증된 주체에게 작업을 허용하는 것을 의미한다. 적절하지 못한 접근을 차단하기 위한 방법과 규칙을 정의하는 접근통제에서 자주 나오는 개념이다. 접근통제는 식별, 인증, 인가 이렇게 3단계로 구성되어 있다. 정보보안 개념에서 살펴보자면,
단계
설명
접근 매체
식별
- 본인이 누구라는 것을 시스템에 밝히는 것 - 인증 서비스에 스스로를 확인시키기 위하여 정보를 공급하는 주체의 활동 - 식별자는 각 개인의 신원을 나타내기에 사용자 책임추적성 분석에 중요한 자료
- 사용자 이름 - 계정명, 계정 번호
인증
- 자신이 누구인지 증명하는 것 - 주체의 신원을 검증하기 위한 사용 증명(verify or prove) 활동 - 본인임을 주장하는 사용자가 진짜 그 사람이 맞다는 걸 시스템이 인정해주는 것
- 암호, PIN 번호 - 생체인증 - 토큰이나 스마트 카드 등
인가
- 인증된 주체에게 작업을 허용하는 것 - 인증된 주체에게 접근을 허용하고 특정 업무를 수행할 권리를 부여하는 과정 - 알 필요성과 관련. 주체에게 어떤 정보가 유용할지 여부와 관계 있는 공인된 형식상의 접근수준
- 접근제어목록(ACL) - 보안 등급
🤓 (기타) HTTP의 발전사 HTTP는 초창기 HTTP/0.9를 시작으로 1.0, 1.1, 2.0을 거쳐 3.0까지 발전했다. 간단하게 공부하자면, (HTTP/0.9) GET 메서드만 사용 가능 (HTTP/1.0) HEAD/POST 같은 다른 메서드 도입 + 헤더 지원하나, HTTP 메시지 주고받을 때마다 연결 수립 종료 반복 (HTTP/1.1) 지속 연결 공식 지원 (HTTP/2.0) 헤더 압축 및 바이너리 데이터 기반 메시지 송수신(이전에는 텍스트 기반), 서버 푸시 기능 제공 및 멀티플렉싱 기법을 활용해 HOL 블로킹 문제 완화함. 멀티플렉싱은 여러 스트림을 이용해 병렬적으로 메시지를 주고받는 기술을 의미함. (HTTP/3.0) UDP를 기반으로 하는 QUIC 프로토콜을 활용하여 동작, 속도 개선(이전 버전은 모두 TCP 사용)
HTTP 헤더와 기반 기술(캐시, 쿠키, 콘텐츠 협상)
# 요청에 활용하는 HTTP 헤더
1) Host 요청을 보낼 호스트를 나타내는 헤더로 주로 도메인 네임으로 명시됨 2) User-Agent 웹 브라우저와 같이 HTTP 요청을 시작하는 클라이언트 측의 프로그램을 의미 웹 브라우저의 Mozilla 호환 여부, 운영체제 및 아키텍처 정보, 렌더링 엔진 관련 정보, 브라우저와 버전 정보 등이 들어감 3) Referer 클라이언트가 요청을 보낼 때 머무르고 있던 URL이 명시됨 4) Authorization 클라이언트의 인증 정보를 담는 헤더. 인증 타입과 인증을 위한 정보credentials를 차례로 명시함
예전에 공부할 때부터 웹 브라우저의 Mozilla 호환 여부가 뭔지 좀 궁금했는데, 공부하다 보니 또 나왔길래 챗지피티한테 물어봤다.
아래는 지피티가 답변해준 내용이다. 요약하자면 초기 웹 브라우저들끼리 호환하기 위해 쓰이던 문구였는데 관습적으로 이어져 내려와 지금은 "현대적인 웹 표준을 잘 지원한다"는 의미로 쓰인다 정도?
# 응답에 활용하는 HTTP 헤더
1) Server 요청을 처리하는 서버 측 소프트웨어와 관련된 정보를 명시 2) Allow 클라이언트에게 허용된 HTTP 메서드 목록을 알려주기 위해 사용됨. 상태코드 405 Method Not Allowed와 함께 사용됨 3) Retry-After 자원을 사용할 수 있는 날짜 또는 시각을 나타냄. 상태코드 503 Service Unavailable과 함께 사용됨 4) Location 클라이언트에게 자원의 위치를 알려주기 위해 사용되는 헤더. 주로 리다이렉션 발생이나 새로운 자원 생성 시 사용됨 5) WWW-Authenticate 자원에 접근하기 위한 인증 방식을 설명하는 헤더. 상태코드 401 Unauthorized와 함께 사용됨
# 요청과 응답에 모두 활용하는 HTTP 헤더
1) Date 메시지가 생성된 날짜와 시각에 관련된 정보를 담은 헤더 2) Connection 클라이언트의 요청과 응답 간 연결 방식을 설정하는 헤더. keep-alive, close가 가장 대표적으로 사용되는 값 3) Content-Length 본문의 바이트 단위 크기(길이) 4) Content-Type, Content-Language, Content-Encoding 전송하려는 메시지 본문의 표현 방식을 설명하는 헤더로 표현 헤더라고도 부름 순서대로 본문에 사용된 미디어 타입, 자연어, 그리고 본문을 압축하거나 변환한 방식을 명시함
# 캐시
불필요한 대역폭 낭비와 응답 지연 방지를 위해 정보의 사본을 임시로 저장하는 기술이자, 이렇게 저장된 데이터 자체를 의미한다. 캐시는 웹 브라우저에 저장(개인 전용 캐시)되거나, 클라이언트와 서버 사이에 위치한 중간 서버(공용 캐시)에 저장되기도 한다. 캐시는 사본 데이터이기 때문에, 최신 원본 데이터와 얼마나 유사한지를 확인하는 캐시 신선도cache freshness라는 개념을 사용한다. 캐시 신선도를 유지하는 가장 기본적인 방법은 캐시된 데이터에 유효 기간을 설정하는 것이다. 기간이 만료되었다면 원본 데이터를 다시 요청해야 하니 캐시 신선도를 유지할 수 있게 된다. 유효기간이 만료된 캐시의 신선도를 재검사하는 방법에는 1) 날짜를 기반으로 서버에게 물어보는 If-Modified-Since 헤더 방식과 2) 엔티티 태그(자원의 버전 식별 정보)를 기반으로 서버에게 물어보는 If-None-match 헤더 방식이 있다.
# 쿠키
서버에서 생성되어 클라이언트 측에 저장되는 데이터로, 상태를 유지하지 않는 HTTP의 특성을 보완하기 위한 수단이다. 쿠키는 기본적으로 <이름, 값> 쌍의 형태를 띠고 있고, 필요시 적용 범위와 만료 기간과 같은 다양한 속성을 추가할 수 있다. 서버는 쿠키를 생성해 클라이언트에게 전송하고, 클라이언트는 추후 동일한 서버에 보내는 요청 메시지에 이 쿠키를 포함하여 전송한다. 서버는 쿠키 정보를 참고해 두 개의 요청이 같은 클라이언트에서 온 것인지(세션 인증), 로그인 상태를 유지하고 있는지 등을 알 수 있게 된다.
쿠키는 정보가 쉽게 노출되거나 조작될 수 있어 보안 위험이 있다. 이를 보완하기 위해 Secure와 HttpOnly라는 속성이 있다. Secure는 HTTPS 프로토콜이 사용되는 경우에만 쿠키가 전송되도록 하는 속성이고, HttpOnly는 HTTP 송수신을 통해서만 쿠키를 이용하도록 제한하는 속성이다. 악의적인 방식으로 쿠키를 중간에 가로채거나 위변조 할 위험이 있어, 이런 상황을 방지하기 위해 자바스크립트와 같이 다른 방식으로는 쿠키에 접근하지 못하게 하는 속성이다.
# 콘텐츠 협상과 표현
같은 URI에 대해 가장 적합한 자원의 형태를 제공하는 메커니즘을 의미한다. 같은 URI로 식별 가능한 HTML 문서라 해도, 영어로 요청하는지 한국어로 요청하는지에 따라 알맞은 형태로 제공해 주는 것이다. 지역이나 언어 설정에 따라 구글과 같은 사이트들이 다른 페이지를 보여주는 이유기도 하다. 이때 송수신 가능한 자원의 형태를 자원의 표현representation이라고 한다. 그래서 콘텐츠 협상은 클라이언트에게 가장 적합한 자원의 표현을 제공하는 메커니즘을 뜻한다.
📚 혼공단 기본 숙제
# (p271) 확인문제 1번 "도메인 네임과 네임 서버에 대한 설명으로 옳지 않은 것을 골라 보세요" >> 답은 4번이다. www.example.com에서 루트 도메인은 com이 아니라 가장 마지막에 생략된 점(.)에 해당한다.
# (p307) 확인문제 2번 "HTTP 상태 코드에 대한 설명으로 옳지 않은 것을 골라 보세요" >> 답은 1번이다. 300번대 상태 코드는 리다이렉션에 관련된 코드이다. 요청한 자원이 존재하지 않는, 자원을 찾을 수 없다는 응답은 404 Not Found에 더 가깝다.
📚 혼공단 추가 숙제 : HTTP 요청 메시지 확인해 보기
한빛미디어 사이트 중 하나에 들어가 보았다. 왼쪽 그림을 통해 css, js 등 페이지 접근 과정에서 주고받은 자원들의 목록이 쭉 나오는 걸 볼 수 있다. 그중 하나를 열어 더 자세히 들어가 보자. 헤더 부분을 클릭했더니 간단한 요약과 요청/응답헤더 내용을 보여준다. 아까 배운 상태 코드가 200 OK로 나오는 것도 볼 수 있고, GET 메서드를 사용해 요청한 것도 볼 수 있다. 이런 식으로 웹이 어떻게 동작하는지 살펴보는 건 사이트에 에러가 났을 때 원인 찾기에도 도움이 된다. 오래간만에 보니까 재밌고 좋네,,,
이렇게 해서 미리 하는 5주 차 예습도 마치겠읍니다. 사실 DNS며 쿠키며 개념들 다 들어는 본거잔아요. 대학 다니며 공부했는데 기억은 사라지고 단어 껍데기만 남아버렸을 뿐... 그래서 자세히 뜯어보면 사실은 모른다에 가까운 개념들을 복습도 하고 또 미처 몰랐던 세세한 부분까지 알게 된 것 같아 뿌듯하내요^^7
연휴 잘 보내셨나요? 혼공단 방학인 김에 다른 공부들 더 하려고 했는데요 역시 개같이 실패^^하고 2월이 되었읍니다 지난달에 혼공단이라도 해서 다행이지 뭐예요 아니었음 아무것도 못 이룬 사람 될 뻔 하지만 벌써 혼공단 절반이나 잘 마친 사람이 되었다 (혼공단 짱 자주 해조요) 아무튼 다시 돌아온 혼자 공부하는 네트워크 4주 차에 할 일은요 네 번째 챕터인 전송 계층을 공부하고
<목차> Chapter 1. 컴퓨터 네트워크 시작하기 Chapter 2. 물리 계층과 데이터 링크 계층 Chapter 3. 네트워크 계층 Chapter 4. 전송 계층 Chapter 5. 응용 계층 Chapter 6. 실습으로 복습하는 네트워크 Chapter 7. 네트워크 심화
혼공단 숙제로 작업 관리자에서 프로세스별 PID 확인해 보는 거라죠
지난 내용 복습하기
저번에도 말했지만 제가 혼공단을 하는 목적은 뇌에 뭐라도 남기기입니다 본격적인 전송 계층 공부에 앞서 네트워크 계층까지 복습부터 해볼게요
계층명
지난 주 핵심
다 합쳐서 복습하기
네트워크
인터넷 프로토콜 IP IP 주소(IPv4, IPv6) ARP(IP to MAC) 네트워크 클래스 NAT(공인/사설IP) DHCP(IP 동적할당) 라우팅 프로토콜 (내부 RIP&OSPF, 외부 BGP)
- 메시지를 다른 네트워크에 속한 수신지까지 전달하는 계층 = 네트워크 간 통신 계층 - IP는 데이터그램 기반 비신뢰성, 비연결성 서비스로, IP 단편화(패킷의 분해 및 조립), IP 주소 지정, 경로 선택 기능을 가짐 - 개방 시스템 들 간 네트워크 연결 설정/유지/관리 기능, 데이터의 교환/중계 기능, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행함 - 전송 단위는 패킷 - 장비로는라우터 - 관련 프로토콜로는 IP, ICMP, IGMP, ARP, RARP 등
- IPv4는 4바이트(32비트)+10진수 표현, 클래스 단위로 비순차적으로 할당함. 보안 기능이 없으며, 패킷 크기에 제한(64바이트)이 있음. 유니캐스트/브로드캐스트/멀티캐스트 방식을 사용함 - IPv6는 16바이트(128비트)+16진수 표현, 네트워크/단말 순서로 순차적으로 할당함. 확장 헤더를 사용해 인증/보안 기능을 포함하며, 패킷 크기에 제한이 없음. 유니캐스트/멀티캐스트/애니캐스트 방식을 사용함
- 하나의 IP 주소는 네트워크 주소와 호스트 주소로 구성된 - (클래스 풀 주소 체계) 네트워크 크기에 따라 IP 주소를 분류하는 걸 클래스라 함. 클래스는 A~E까지 5개 존재. 클래스 풀 주소는 네트워크 크기가 고정이라는 한계가 존재함 - (클래스리스 주소 체계) 네트워크 주소는 1로, 호스트 주소는 0으로 표기하여 임의로 나누는 방식을 서브넷 마스크라 함. IP 주소와 서브넷 마스크를 비트 AND 연산하면 네트워크 주소가 나온다. 서브넷 마스크는 10진수로 표기하거나, IP 주소/서브넷 마스크 상 1의 개수 형식으로 표현하는 CIDR 표기법을 사용함
- ARP 프로토콜은 "동일 네트워크 내에서" IP 주소를 통해 MAC 주소를 알아내는 과정. ARP 요청(브로드캐스트) > ARP 응답(유니캐스트) > ARP 테이블 갱신 순으로 동작한다. - NAT는 공인 IP와 사설 IP를 상호 변환해주는 기술 - DHCP는 네트워크 안의 호스트들에게 IP와 DNS 서버, 서브넷 마스크 주소를 동적으로 할당하는 프로토콜. DHCP 할당은 DISCOVER, OFFER, REQUEST, ACK 4단계로 구성됨(모두 브로드캐스트).
- 라우팅 프로토콜은 라우터끼리 자신들의 정보를 교환하며 패킷이 이동할 최적의 경로를 찾고자 사용. AS 내부에서 수행되면 IGP로 RIP와 OSPF가 있고, 외부에서 수행되면 EGP로 BGP가 있음 - IGP는 거리 벡터를 사용하는 RIP와 링크 상태를 사용하는 OSPF/IS-IS로 나뉨
데이터 링크
NIC 스위치 (전이중 통신+VLAN)
- 네트워크 내 주변장치 간 정보를 올바르게 주고받기 위한 계층 - MAC 주소 체계를 통해 네트워크 내 송수신지를 특정 - 물리적으로 연결된 인접한 개방 시스템들 간 신뢰/효율적 정보 전송을 위해 시스템 간 연결 설정과 유지 및 종료 담당 - 오류 검출 및 회복을 위한 오류 제어, 송수신측 속도 차이 해결을 위한 흐름 제어, 프레임 순서적 전송을 위한 순서 제어 기능을 가짐 - 전송 단위인 프레임에 물리적 주소를 부여함 - 장비로는 랜카드, 브리지, 스위치 등 - 관련 프로토콜로는 HDLC, LAPB, LLC, MAC, LAPD, PPP, 이더넷 등
- 스위치는 전이중 통신을 한다. MAC 주소 학습과 테이블을 이용해, 특정 MAC 주소를 가진 호스트에만 프레임을 전달할 수 있다. MAC 주소 학습은 플러딩, 포워딩과 필터링, 에이징을 통해 이루어진다. - 스위치는 또한 가상의 LAN을 만드는 VLAN 기능을 지원한다.
물리
트위스티드 페어 케이블 광섬유 케이블 허브(반이중 통신+CSMA/CD)
- OSI 모델 최하단 계층 - 0과 1로 표현되는 비트 신호를 주고 받음 (전송단위가 Bit) - 통신 케이블로 데이터를 전송하는 물리적 장비에 필요한 기계/전기/기능/절차적 특성에 대한 규칙을 정의 - 장비로는 통신 케이블, 리피터, 허브 등 - 관련 프로토콜로는 RS-232C, X.21 등 - 허브는 반이중 통신을 해서 무전기처럼 송수신을 번갈아 가면서 한다. 다른 호스트가 기다리지 않고 신호를 보낼시 충돌 위험이 있는데 이를 방지하는 프로토콜이 CSMA/CD이다. Carrier Sense(캐리어를 감지하고) Multiple Access(다중 접근시에) Collision Detection(충돌을 검출)한다.
이것 뭐예요...? 정리하고 보니 3주 차 네트워크 계층에서 공부한 게 엄청 많네? 네트워크 계층의 가장 큰 특징이자 한계는 신뢰할 수 없는 비신뢰성이자 비연결형 프로토콜이라는 점인데요. IP 프로토콜은 패킷을 전달할 때, 패킷이 수신지까지 제대로 전송되었다는 보장을 해주지 않기 때문이에요. 다른 말로 최선형 전달 best effort delivery 라고도 한다는데요. 최선을 다해 전송은 해보겠지만, 그 결과는 보장하지 못한다는 의미래요. 약간 역설적인데,,, 또한, 송수신 호스트 간에 사전에 연결 작업을 하지 않아요. 성능이 더 중요하기에 수신지를 향해 패킷을 전송만 합니다.
연결형 통신 + 신뢰성 있는 통신 = 전송 계층
이 두 한계를 보완하는 계층이 오늘 배우게 될 전송 계층이에요. 전송 계층에는 가상의 회선을 설정하듯 연결을 수립하고, 송수신하는 동안에는 계속 유지하는 연결형 프로토콜인 TCP가 있어요. 그리고 패킷이 수신지까지 올바른 순서대로 확실히 전달되는 것을 보장하고자, 재전송을 통한 오류 제어, 흐름 제어, 혼잡 제어와 같은 기능도 제공합니다. 또한, 성능이 더 중요한 경우를 지원하고자 비연결형 통신 프로토콜인 UDP도 있어요. 여기에 더해 상위 계층인 응용 계층과의 연결 다리 역할을 하기도 한다고 하는데요. 실행 중인 특정 애플리케이션까지 패킷이 전달되기 위해서는 패킷에 특정 어플리케이션을 식별할 수 있는 정보가 있어야 해요. 이를 포트라 하는데요, 전송 계층에서는 패킷 내의 송/수신지 포트 번호를 통해 송/수신지 호스트의 어플리케이션을 식별합니다.
# 포트 port
포트 번호는 16비트로 표현 가능하며, 사용가능한 포트의 수는 2^16 = 65,536개이다. 즉, 할당 가능한 포트 번호는 0번부터 65,535번까지이다. 포트 번호는 번호 범위에 따라 세 종류로 나눈다.
잘 알려진 포트와 등록된 포트는 인터넷 할당 번호 관리 기관(IANA)에서 할당하고 관리한다. 자세한 목록을 보고 싶다면 IANA 홈페이지에서 확인 가능하다. 하지만 여기의 포트 번호는 권고일 뿐 강제는 아니다.
IP 주소와 포트 번호가 함께 제공되면, 특정 호스트에서 실행 중인 특정 어플리케이션 프로세스를 식별할 수 있게 된다. 그래서 포트 번호는 IP 주소:포트 번호 형식으로 사용되는 경우가 많다.
IP 주소
:
포트 번호
호스트 식별
어플리케이션 프로세스 식별
# 포트 기반 NAT, NAPT
NAT는 IP 주소를 변환하는 기술로, 주로 네트워크 내부의 사설 IP 주소와 네트워크 외부의 공인 IP 주소를 변환하는 데 사용된다. 하지만 만약 1:1로 매핑해서 사용한다면, 공인 IP 주소 수가 부족하여 수없이 많은 사설 주소를 모두 변환해서 사용하기가 어렵다. 그래서 요즘의 NAT 기술은 변환하고자 하는 다수의 사설 IP 주소를 그보다 적은 수의 공인 IP 주소로 변환할 수 있게 하는데, 이때 포트를 활용한다. 포트 기반의 NAT를 NAPT(Network Address Port Translation)이라 한다. NAPT는 포트를 활용해 하나의 공인 IP 주소를 여러 사설 IP 주소가 공유할 수 있도록 하는 NAT의 일종이다. NAT 테이블에 변환할 IP 주소 쌍과 함께 포트 번호를 기록하고, 변환 시에 참고하는 방법이다. 포트 번호를 통해 네트워크 내부 호스트를 특정할 수 있기에, 다수의 사설 IP 주소를 그보다 적은 수의 공인 IP 주소로 변환할 수 있게 된다. N:1로 매핑할 수 있어 공인 IP 주소 수 부족 문제를 개선하는 것이다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함
# 추가 학습 from 네트워크 계층, ICMP
추가 학습 내용으로 IP의 비신뢰성/비연결성 전송 특성을 보완하기 위한 네트워크 계층의 프로토콜을 알아보자 전송 계층의 내용은 아니라 헷갈림 방지를 위해, 오늘도 접어두기 기능을 적극 활용합니다^^
💡 ICMP(Internet Control Message Protocol) - IP 패킷의 전송 과정에 대한 피드백 메시지를 얻기 위해 사용하는 프로토콜 - 호스트 서버와 인터넷 게이트웨이 사이에서 메시지를 제어하고 오류 처리와 전송 경로의 변경 및 파악을 위한 프로토콜임 - IP 데이터그램을 사용하지만, 메시지는 TCP/IP 소프트웨어에 의해 처리되는 특징을 가짐
- ICMP 메시지 종류로는 크게 1) (오류 보고) 전송 과정에서 발생한 문제 상황에 대한 오류 보고 2) (질 의) 네트워크에 대한 진단 정보 = 네트워크상의 정보 제공 - ICMP 메시지는 ICMP 패킷 헤더에 포함되어 있는 타입과 코드 정보로 정의한다. ICMP 패킷 헤더의 타입 필드에는 ICMP 메시지의 유형을 번호로, 코드 필드에는 구체적인 메시지 내용을 번호로 명시한다.
[ICMP 오류 보고 메시지의 특징] - 어떠한 ICMP 오류 메시지도 ICMP 오류를 운반하는 데이터그램의 응답으로 생성되지 않음 - 어떠한 ICMP 오류 메시지도 처음 단편이 아닌 단편 데이터그램을 위해 생성되지 않음 - 어떠한 ICMP 오류 메시지도 멀티캐스트 주소를 가진 데이터그램을 위해 생성되지 않음 - 어떠한 ICMP 오류 메시지도 127.0.0.0, 0.0.0.0과 같이 특수 주소를 가진 데이터그램을 위해 생성되지 않음
[ICMP 오류 보고 메시지 종류] - (Type 3) 목적지 도달 불가, Destination Unreachable 데이터그램이 최종 목적지에 왜 도착하지 못했는지에 대한 오류를 정의, 0~15까지의 다른 코드를 사용함 (코드 0) 네트워크 도달 불가, (코드 1) 호스트 도달 불가, (코드 2) 프로토콜 도달 불가, (코드 3) 포트 도달 불가, (코드 4) 단편화가 필요하나 DF가 1이라 단편화 불가 - (Type 4) 근원지 억제, Source Quench 네트워크 충돌이 발생해서 데이터그램이 폐기되었음을 송신자에게 알림. 메시지를 받은 송신자(근원지)는 데이터그램 송신 과정을 천천히 억제하여 수행한다. 이를 통해 IP 프로토콜에 혼잡제어 메커니즘을 추가하는 셈 - (Type 5) 재지정 메시지, Redirection 발신자가 메시지 전송에 잘못된 라우터를 사용할 때 이용됨. 라우터는 발신자에게 향후 디폴트 라우터로 변경하라고 알리는 메시지를 보낸다. 그래서 메시지 안에 디폴트 라우터의 IP 주소가 포함됨 - (Type 11) 시간 경과, Time Exceeded 타임아웃 발생으로 IP 패킷이 폐기되었음을 알림. 타임아웃 사유는 코드를 통해 확인함 (코드 0) TTL 만료. 최종 목적지 도달 전에 TTL값이 0이 되어 폐기됨 (코드 1) 패킷 재조합 타임 만료. 보통 IP 데이터그램 일부 단편이 전송과정에서 손실되어 재조합에 실패할 시 발생. 패킷 재조합 과정에서 타임아웃이 발생하여 해당 IP 데이터그램이 모두 폐기되었음을 알림 - (Type 12) 매개변수 문제, Prameter Problem (코드 0) 데이터그램의 헤더에 문제, (코드 1) 어떤 옵션에 문제(옵션 없음/의미 파악 불가 등)가 있을 때 사용
[ICMP 질의 메시지 종류] 인터넷에서 호스트/라우터가 활성화되었는지, 두 장치 사이 IP 데이터그램이 단/양방향인지 확인할 때 주로 사용함 - (Type 8) 에코 요청, Echo Request - (Type 0) 에코 요청 응답, Echo Reply - (Type 9) 라우터 광고 라우터가 호스트에게 자신을 알릴 때 사용
* ping은 네트워크 상태를 진단하는 가장 기본적인 명령어로, ICMP 에코 요청과 에코 응답 메시지를 기반으로 구현됨 그 외에도 traceroute/tracert도 ICMP 메시지를 기반으로 동작함. 참고하시라~
전송 계층 프로토콜, TCP와 UDP
# TCP 통신 단계와 세그먼트 구조
TCP는 데이터를 송수신하기 전에 연결을 수립하고, 통신이 끝나면 연결을 종료한다. 그리고 데이터 송수신 과정에서 재전송을 통한 오류 제어, 흐름 제어, 혼잡 제어 등의 기능을 제공한다.
1단계
2단계
3단계
연결 수립
>>>
데이터 송수신 (재전송을 통한 오류/흐름/혼잡 제어)
>>>
연결 종료
MSS(Max Segment Size)는 TCP로 전송할 수 있는 최대 페이로드 크기를 의미한다. MSS 크기 고려 시 TCP 헤더의 크기는 제외한다. 간단하게 그려보자면 아래와 같은 느낌이다.
IP MTU (헤더 포함)
이더넷 헤더
IP 헤더
TCP 헤더
페이로드
FCS
TCP MSS
계속해서 TCP 세그먼트 구조를 살펴보고자 한다. 간단하게 그려보면 아래와 같은데,
0
4
8
12
16
32
송신지 포트
수신지 포트
순서 번호(SEQ NUM)
확인 응답 번호 (ACK NUM)
데이터 오프셋
예약
제어 or 플래그 비트
CWR
ECE
URG
ACK
PSH
RST
SYN
FIN
윈도우
체크섬
긴급 포인터
옵션
- 송/수신지 포트 : 송/수신지 애플리케이션을 식별하는 포트 번호가 기재된 필드 - 순서 번호 : 송수신되는 세그먼트의 올바른 순서 보장을 위해 세그먼트 데이터의 첫 바이트에 부여되는 번호 - 확인 응답 번호 : 상대 호스트가 보낸 세그먼트에 대한 응답. 다음으로 수신하기를 기대하는 순서 번호를 명시함 - 제어 or 플래그 비트 : 현재 세그먼트에 대한 부가정보를 나타냄. 기본적으로 8비트로 구성. 각 자리의 비트는 각기 다른 의미를 가짐 >> ACK : 세그먼트 승인을 나타내는 비트 >> SYN : 연결을 수립하기 위한 비트 >> FIN : 연결을 종료하기 위한 비트 - 윈도우 : 한 번에 수신하고자 하는 데이터의 양을 나타내는 수신 윈도우의 크기를 명시 🧐 순서 번호와 확인 응답 번호에 대해 조금 더 알아보자 만약 전송할 데이터가 1900바이트이고, MSS가 500바이트라고 가정한다면, 이 데이터는 4개의 세그먼트로 나눌 수 있다. 처음 통신을 위해 연결을 수립했다면(제어비트 SYN 플래그가 1이라면), 순서 번호는 무작위값이 된다. 이를 초기 순서 번호(ISN)이라 한다. 연결 수립 이후 데이터를 송신하는 동안 순서 번호는 송신한 바이트를 더해가는 누적 형태가 된다. 즉,순서 번호는 초기 순서 번호 + 송신한 바이트 수가 되는 셈이다. 만일 초기 순서 번호가 100이라면, 이후 세그먼트들의 순서 번호는 초기 순서번호 +500, +1000, +1500 순으로 증가하게 된다.
출처 : 혼공네트 유튜브 강의 내 장표 캡쳐함
확인 응답 번호는 순서 번호에 대한 응답이다. "다음에는 이거 보내조요 or 다음에 받아야 하는 애는 이거임 내놔"하고 알려주는 값이다. 즉, 수신자가 다음에 받기를 기대하는 순서 번호로, 일반적으로 수신한 순서번호 +1로 설정한다. 확인 응답 번호 값을 보낼 때는 제어비트 ACK 플래그 값을 1로 설정하고, 확인 응답 번호에 수신한 순서 번호+1을 설정하면 된다.
# TCP 연결 수립 : 3 웨이 핸드셰이크
TCP의 연결 수립은 3개 단계로 이루어진다. 우선 그림으로 살펴보면 이렇다.
출처 : 도서 용어노트에 추가 필기함
그림만으로는 이해가 안 가니까 단계별로 추가적인 설명을 해보면,
단계
TCP 상태
송수신 방향
세그먼트
세그먼트 주요 정보
비유
CLOSED / LISTEN : 연결이 수립되지 않은 상태
1단계 액티브 오픈
SYN-SENT
A >> B
SYN
- 호스트 A의 초기 순서 번호 - 1로 설정된 SYN 비트
우리 연결하자
2단계 패시브 오픈
SYN-RECEIVED
B >> A
SYN+ACK
- 호스트 B의 초기 순서 번호 - 호스트 A 전송 세그먼트에 대한 확인 응답 번호 - 1로 설정된 SYN 비트와 ACK 비트
ㅇㅇ 확인함 연결하자 ㄱㄱ
3단계 연결 확립
ESTABLISHED
A >> B
ACK
- 호스트 A의 다음 순서 번호 - 호스트 B 전송 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트
ㅇㅇ 확인함
이렇게 연결이 되고 나면, 필요한 만큼 데이터 송수신을 하면 된다죠.
중요한 개념이라 잘 알아둬야 함... 왜냐? 언제나 그렇듯 시험에 자주 나와요^ㅁ^ 이런 식으로...
출처 : 한국은행 전공학술 기출 예시문제
이제 이 문제를 풀 수 있다. TCP 3-way handshake니까 TCP 연결 수립이다. HOST B가 패시브 오픈이니까 SYN에 대한 응답으로 ACK =24(23+1)을 보내고, 자신의 SYN 패킷에는 초기 순서 번호로 20(21-1)을 담아 보내면 된다. 일반적으로 수신한 번호+1을 보내기 때문! SYN Flooding 공격은... 너무 길어지니까 나중에 공부하자(빈 말)
# TCP 연결 종료 : 4 웨이 핸드셰이크 데이터 송수신이 끝났다면 연결을 종료해야 한다죠. TCP가 연결을 종료하는 과정은 송수신 호스트가 각자 한 번씩 FIN과 ACK를 주고받으면 된다. 그림으로 또 살펴보자면,
출처 : 도서 용어노트에 추가 필기함
이번에도 그림만으로는 이해가 안 가니까 단계별로 추가적인 설명을 해보면,
단계
TCP 상태
송수신 방향
세그먼트
세그먼트 주요 정보
비유
ESTABLISHED : 열심히 데이터 송수신하는 상태
1단계 액티브 클로즈
FIN-WAIT-1
A >> B
FIN
- 1로 설정된 FIN 비트
우리 연결끊자
2단계 패시브 클로즈
CLOSE-WAIT
B >> A
ACK
- 호스트 A 전송 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트
ㅇㅇ 확인함
FIN-WAIT-2
-
-
상대의 FIN 세그먼트를 기다리는 중
-
3단계 연결 끊기
LAST-ACK
B >> A
FIN
- 1로 설정된 FIN 비트
이제 연결끊어
4단계 확인
TIME-WAIT
A >> B
ACK
- 호스트 B 전송 세그먼트에 대한 확인 응답 번호 - 1로 설정된 ACK 비트
ㅇㅇ 확인함
B(서버)는 마지막 ACK 패킷을 수신하면 바로 CLOSED로 바뀐다. 하지만 A(클라이언트)는 마지막 ACK 세그먼트가 올바르게 전송되지 않을 가능성을 고려하여 일정 시간 기다리는 TIME-WAIT 상태를 가진 후에 CLOSED로 접어든다.
CLOSED : 두 호스트 모두 연결을 종료한 상태
이러면 제대로 연결 종료된 거다. FIN-ACK을 서로 한 번씩 주고받고, 잠시 대기했다가 샤따 내리기 정도로 기억하면 된다죠. 여기서 잠깐! 연결 확립과 연결 종료 모두 TCP 상태라는 개념이 새롭게 등장한다. TCP는 연결형/신뢰형 통신을 위해 다양한 상태를 유지한다. 상태는 현재 어떤 통신 과정에 있는지를 나타내는 정보다. 그래서 TCP를 스테이트풀 stateful 프로토콜이라고도 한다. TCP의 상태는 크게 3가지로 나뉜다. 1) 연결이 수립되지 않은 상태, 2) 연결 수립 과정에서 주로 확인할 수 있는 상태, 3) 연결 종료 과정에서 주로 확인할 수 있는 상태라죠. 각 상태와 의미하는 바를 정리해 보자면,
상태 분류
상태명
설명
연결 수립 X
CLOSED
아무 연결이 없는 상태
LISTEN
일종의 연결 대기 상태 보통 서버로 동작하는 패시브 오픈 호스트는 이 상태를 유지함
연결 수립 중
SYN-SENT
액티브 오픈 호스트가 SYN 세그먼트를 보내고, 그에 대한 응답으로 SYN+ACK 세그먼트를 기다리는 상태 = 연결 요청 후 대기하는 상태
SYN-RECEIVED
패시브 오픈 호스트가 SYN+ACK 세그먼트를 보내고, 그에 대한 응답으로 ACK를 기다리는 상태
ESTABLISHED
연결이 확립되었음을 나타내는 상태 = 데이터 송수신 가능한 상태
연결 종료 중
FIN-WAIT-1
일반적인 TCP 연결 종료의 첫 단계. FIN 세그먼트로 연결 종료 요청을 보낸 후 액티브 클로즈 호스트의 상태
CLOSE-WAIT
FIN 세그먼트의 응답으로 ACK 세그먼트를 보내고, 패시브 클로즈 호스트가 대기하는 상태
FIN-WAIT-2
FIN-WAIT-1 상태에서 ACK를 받으면 FIN-WAIT-2로 상태가 변경됨. 상대의 FIN 세그먼트를 기다리는 상태
LAST-ACK
CLOSE-WAIT 상태에서 FIN 세그먼트를 보내고, 이에 대한 ACK 세그먼트를 기다리는 상태
TIME-WAIT
FIN 세그먼트를 수신한 액티브 클로즈 호스트가 ACK를 전송한 후의 상태. 일정시간 기다린 후에 CLOSED로 바뀐다
CLOSING
보통 동시에 연결을 종료하고자 할 때 전이되는 상태. 서로가 FIN을 보내고 받은 뒤에 ACK를 보냈지만, 아직 자신의 FIN에 대한 ACK는 받지 못했을 때 접어드는 상태이다. 이 경우 ACK를 수신한다면 각자 TIME-WAIT 상태로 들어갔다가 연결을 종료하게 된다.
# UDP : 비연결형, 비신뢰성, 스테이트리스 프로토콜
UDP는 비연결형 통신을 수행하는 신뢰할 수 없는 프로토콜이다. 상태를 유지/활용하지 않기에 스테이트리스 stateless 프로토콜이라고 하기도 한다. 보장하는 내용이 없기에, TCP에 비해 적은 오버헤드로 패킷을 빠르게 처리한다는 장점이 있다. 그래서 실시간 스트리밍 서비스, 인터넷 전화와 같이 패킷이 조금 손실되어도 무방한, 실시간성을 강조하는 상황에서 주로 사용한다. UDP 데이터그램 헤더 구조는 아래와 같다.
0
16
32
송신지 포트
수신지 포트
길이
체크섬
- 송/수신지 포트 - 길이 : 헤더를 포함한 UDP 데이터그램의 바이트 - 체크섬 : 데이터그램 전송 과정의 오류 발생 여부 검사를 위한 필드. 수신지는 이 필드 값을 토대로 정보 훼손 여부를 판별하고, 문제가 있다고 판단한 데이터그램은 폐기함 두 프로토콜도 시험에 자주 나오니까 정리하고 넘어가자면,
TCP
UDP
- 연결형 서비스 - 가상 회선 방식 (하나의 회선 사용 = 1:1 통신) - 패킷 전송 순서 보장 및 수신 여부 확인 - 송수신부간 연결 확인 - 데이터의 신뢰성 높음 - 속도 느림 - HTTP 통신, 이메일/파일 전송 등에 사용 - 오류, 흐름, 혼잡 제어 제공
- 비연결형 서비스 - 데이터그램 패킷 교환 방식(서로 다른 회선 활용) - 패킷 순서 보장 X 및 수신 여부 확인도 X - 데이터 신뢰성 낮음 - 속도 빠름 - 실시간 서비스 - 체크섬을 활용한 오류 검출 가능
TCP의 오류, 흐름, 혼잡 제어 기능
TCP는 자신의 신뢰성을 보장하기 위해, 재전송을 기반으로 다양한 오류를 제어하고, 흐름 제어를 통해 처리 가능한 양만큼만 데이터를 주고받으며, 혼잡 제어를 통해 네트워크 상태에 따라 전송량을 조절한다. 각각의 기능에 대해 자세히 알아보자.
# TCP 오류 제어 : 재전송 기법
TCP 세그먼트에는 오류 검출용 체크섬 필드가 있다. 하지만 이 체크섬은 수신 호스트가 수행하는 훼손 여부 체크에만 사용될 뿐이다. 송신 호스트가 세그먼트 전송 과정에 문제가 있다는 걸 인지하는데 쓰이지는 않는다. 그런데 TCP가 제 기능을 하려면, 1) 송신 호스트가 자기가 보낸 세그먼트에 문제가 있다는 걸 알아야 하고, (오류 감지) 2) 이 사실을 알게 되면 해당 세그먼트를 다시 보낼 수 있어야 한다 (재전송) TCP는 오류를 검출/감지하고 세그먼트를 재전송해야 한다고 판단하는 상황은 크게 2가지로 나눈다.
1) 중복된 ACK 세그먼트를 수신했을 때 수신 호스트는 자신이 받은 세그먼트 순서 번호 중 일부가 누락되었다면 중복된 ACK를 보내게 된다. 중복된 ACK가 도착한다는 건, 송신 호스트가 보낸 세그먼트 중 일부가 상대에게 제대로 도착하지 않았음을 의미한다. 2) 타임 아웃이 발생했을 때 TCP 세그먼트 송신 호스트는 모두 재전송 타이머라는 값을 사용한다. 자신이 세그먼트를 전송할 때 이 타이머를 시작하게 되는데, 이 타이머의 정해진 시간이 끝날 때까지(타임아웃) ACK가 오지 않으면, 세그먼트가 상대에게 정상적으로 도착하지 않았다고 간주한다.
출처 : 혼공네트 유튜브 강의 내 장표 쌔비지
이렇게 수신 호스트가 보내온 ACK와 재전송 타이머를 토대로 문제를 인지한 TCP는 오류가 발생한 메시지를 재전송한다. 이를 ARQ(자동 재전송 요구, Automatic Repeat Request)라 한다. ARQ는 종류가 다양한데, 그중 가장 유명한 세 가지는
1) Stop-and-Wait ARQ = 정지-대기 제대로 전달했음을 확인하기 전까지는 새로운 메시지를 보내지 않음. 세그먼트 송신 후 이에 대한 ACK 세그먼트가 와야만 다음 세그먼트를 보내는, 가장 단순하고 높은 신뢰성을 보장하는 방식이다. 하지만 네트워크 이용 효율과 성능이 저하된다는 단점도 있다. 2) Go-Back-N ARQ 파이프라이닝을 활용해 여러 세그먼트를 전송하고, 도중에 잘못 전송된 세그먼트가 있다면 해당 세그먼트부터 전부 다시 보내는 방식이다. 잘못 전송되었음을 아는 방법은, 타임아웃이 발생했거나 타임아웃 전에 세 번의 동일한 ACK가 수신되는 것이다. 후자의 상황에서 바로 세그먼트를 다시 보내는 걸 빠른 재전송이라 한다. 수신 호스트는 잘못 전송된 세그먼트 이후의 모든 세그먼트는 정상 여부에 관계없이 폐기한다. 송신 호스트에서 잘못 전송된 세그먼트부터 전부 다시 보낼 예정이기 때문이다. 이 방식에서 순서번호 n에 대한 ACK 세그먼트는 n번까지의 확인 응답에 해당한다(누적 확인 응답) 3) Selective Repeat ARQ 동일하게 파이프라이닝을 활용한다. 하지만 제대로 송수신된 세그먼트는 ACK 응답을 보내는 방식이다(개별 확인 응답) 송신 호스트는 ACK 응답이 오지 않은, 잘못 전송된 세그먼트 하나만 다시 보내면 된다. 불필요한 재전송을 피하는 대신 수신 호스트의 처리 절차가 복잡해진다. 잡음이 많은 경우에 효과적
출처 : 컴퓨터 네트워크 하향식 접근 6판 원서
# TCP 흐름 제어 : 슬라이딩 윈도우
파이프라이닝 기반의 Go-Back-N과 Selective Repeat을 활용하면 한 번에 여러 세그먼트를 보내게 된다. 그런데, 수신 호스트가 한 번에 받아서 처리할 수 있는 세그먼트 양은 한정되어 있다. 수신된 세그먼트가 애플리케이션 프로세스에 의해 읽히기 전에 임시로 저장되는 공간을 수신 버퍼라 하는데, 이 공간보다 더 많은 데이터를 보내면 버퍼가 넘쳐 처리가 불가하기 때문이다. 그래서 송신 호스트는 수신 호스트의 처리 속도를 고려하며 송수신 속도를 균일하게 유지하는, 흐름 제어를 사용해야 한다. 흐름 제어에는 슬라이딩 윈도우를 사용한다. 윈도우란 송신 호스트가 파이프라이닝해서 보낼 수 있는 최대량을 의미한다. 윈도우의 크기만큼은 ACK 응답 없이도 한 번에 전송이 가능하다. 윈도우 값은 TCP 세그먼트 내 윈도우 필드를 통해 확인 가능하다. 자세한 건 아래 그림을 보면서 이해해 보자. 만약 수신 호스트가 첫 번째 세그먼트를 올바르게 수신했다면 , ACK를 보내고 수신 윈도우를 오른쪽으로 한 칸 이동한다. ACK를 받은 송신 호스트도 송신 윈도우를 오른쪽으로 한 칸 이동한다. 이렇게 계속 오른쪽으로 미끄러지듯 움직이면서 흐름을 제어해서 슬라이딩 윈도우라고 부른다죠.
출처 : 혼공네트 유튜브 강의 내 장표 쌔비지하고 추가 필기
# TCP 혼잡 제어 : 혼잡 윈도우와 AIMD - 느린 시작, 혼잡 회피, 빠른 회복
혼잡 congestion 이란 많은 트래픽으로 인해 패킷의 처리 속도가 느려지거나 유실될 우려가 있는 네트워크 상황을 의미한다. 송신 호스트는 네트워크 혼잡도를 판단하고 혼잡한 정도에 맞춰 유동적으로 전송량을 조절하며 혼잡 제어를 수행한다. 혼잡 윈도우는 혼잡 없이 전송할 수 있을 법한 데이터의 양을 의미한다. 요 정도 양이면 혼잡 없이 전송 가능하겠지?! 라고 예측할 때, 요 정도에 해당하는 양을 말한다죠. 혼잡 윈도우가 크면 한 번에 전송할 수 있는 세그먼트의 수가 많다는 의미다. 그런데, 혼잡 윈도우의 크기는 언제나 똑같으면 안된다. 네트워크 상황에 따라 유동적으로 바뀌기 때문. 그래서 혼잡 윈도우 크기로 어느 정도가 적당할지 결정해야 하는데, 이때 사용하는 방법을 혼잡 제어 알고리즘이라 한다.
# 가장 기본적인 혼잡 제어 알고리즘 AIMD
AIMD는 Additive Increase/Multiplicative Decrease 의 약자로, "합으로 증가, 곱으로 감소"라는 의미를 가지고 있다. 혼잡이 감지되지 않을 때는 혼잡 윈도우를 RTT*마다 1씩 선형적으로 증가시키고, 혼잡이 감지된다면 혼잡 윈도우를 절반으로 뚝 떨어뜨리는 동작을 반복하는 알고리즘이다. 그래서 혼잡 윈도우가 톱니 모양으로 변화한다는 특징을 가진다. 초기 전송 속도가 느리다는 단점이 있으나, 시간이 지나면 여러 송신 측이 네트워크 대역폭을 공평하게 사용할 수 있다. 하지만 AIMD 하나로는 혼잡 제어가 어렵기에, 추가적으로 느린 시작, 혼잡 회피, 빠른 회복이라는 세 알고리즘을 같이 사용한다.
1) 느린 시작 Slow start 혼잡 윈도우를 1부터 시작해 문제없이 수신된 세그먼트 하나당 1씩 증가시키는 방법으로, 혼잡 윈도우는 RTT마다 2배씩 지수 증가한다. 혼잡 윈도우 크기 증가가 느린 AIMD에 비해, 초기 전송 속도를 상대적으로 빠르게 확보 가능하다는 장점이 있다. 하지만 계속 지수로 증가하면 혼잡 발생 확률이 높아지기에, 느린 시작 임계치 threshold라는 값을 정한다. 타임아웃이 발생하거나, 세 번의 중복된 ACK 세그먼트가 발생하거나, 혼잡 윈도우 값이 느린 시작 임계치 이상이 되어 혼잡이 감지된다면 각각 이렇게 대응한다. >> 타임아웃 발생 : 혼잡 윈도우 값을 1로, 느린 시작 임계치 값은 혼잡 감지 당시의 윈도우 값의 절반으로 초기화하고 느린 시작 재개 >> 세 번의 중복 ACK 발생 : (빠른 재전송 후) 빠른 회복 수행 >> 혼잡 윈도우가 느린 시작 임계치 이상 : 느린 시작 종료, 혼잡 윈도우를 절반으로 초기화하고 혼잡 회피 수행
2) 혼잡 회피 Congestion Avoidance RTT마다 혼잡 윈도우를 1 MSS(Max segment size)씩 증가시키는 방법으로, 혼잡 윈도우가 선형 증가한다. 혼잡 회피 알고리즘에서 혼잡이 감지된다면 각각 이렇게 대응한다. >> 타임아웃 발생 : 혼잡 윈도우 값을 1로, 느린 시작 임계치 값은 혼잡 감지 당시의 윈도우 값의 절반으로 초기화하고 다시 느린 시작 수행 >> 세 번의 중복 ACK 발생 : 혼잡 윈도우와 느린 시작 임계치 값을 대략 절반으로 낮추고 빠른 회복 수행
3) 빠른 회복 Fast Recovery 세 번의 중복 ACK가 발생했을 때 느린 시작은 건너뛰고 혼잡 회피를 수행하는 방법으로, 빠른 전송률 회복을 위해 사용한다. 단, 타임아웃이 발생 시 혼잡 윈도우 값을 1로, 느린 시작 임계치 값은 혼잡 감지 당시의 윈도우 값의 절반으로 초기화하고 다시 느린 시작 수행한다.
그림과 함께 보면 이런 식으로 진행된다죠
출처 : 한국은행 전공학술 기출 예시문제
💡 RTT = Round Trip Time 메시지를 전송한 뒤 그에 대한 답변을 받는 데까지 걸리는 시간을 의미 세그먼트 한 개를 전송하고, 그에 대한 ACK를 수신하는 데까지 걸리는 시간을 RTT라고 보면 된다죠
# 추가 학습: TCP의 신뢰성 보장
관련해서 공부한 내용이 많으니까 짧게 요약해볼게요
TCP는 데이터의 신뢰성을 보장하기 위해 오류 제어, 흐름 제어, 혼잡 제어를 한다. [오류 제어] 데이터 오류/유실 발생 시 재전송을 통해 신뢰성을 보장하려는 방식 [흐름 제어] 데이터 송수신측간 데이터 처리 속도 차이로 인한 데이터 손실을 방지하려는 방식. 수신 측이 주체 [혼잡 제어] 데이터 송신 측의 데이터 전달 속도와 네트워크의 속도 차이로 인한 데이터 손실을 방지하려는 방식. 송신 측이 주체
📚 혼공단 기본 숙제
# (p206) 확인문제 1번 "IP와 연관된 통신 특성으로 알맞은 단어를 보기에서 골라보세요" >> 답은 비신뢰성과 비연결형이다. IP 프로토콜은 패킷이 수신지까지 제대로 전달되었다는 보장을 하지 않고(비신뢰), 사전 연결 작업 없이(비연결) 수신지를 향해 패킷을 보내기만 하기 때문이다. # (p225) 확인문제 2번 "다음은 TCP 쓰리 웨이 핸드셰이크 과정을 나타내는 그림입니다. 괄호 안에 들어갈 말을 보기에서 골라보세요" >> 답은 ACK다. 호스트 A가 먼저 SYN을 보냈고, 이에 호스트 B가 응답하는 ACK+연결을 위한 SYN을 보냈다. 호스트 A는 B가 보낸 2번째 SYN에 ACK 세그먼트를 보내 응답해야 하는 상황이다.
📚 혼공단 추가 숙제 : 작업 관리자에서 프로세스별 PID 확인해보기
나는 맥북이라 작업 관리자 대신 "활성 상태 보기" 메뉴에서 확인해 보았다. 내가 지금 뭐 하는 중인지가 투명하게 나오죠,,, 저는 지금 음악 프로세스(PID 495)로 노래를 들으면서, 사파리(PID 489)로 포스팅을 작성하고 있구요. 궁금한 거 생기면 물어보려고 내 칭구 ChatGPT(PID 930)를 켜놨고요, 숙제하려고 활성 상태 보기(PID 1648)도 켜뒀어요^ㅁ^
이전 회차들과 달리 포스팅을 이틀에 나눠서 했더니 뭔가 내용이 중구난방처럼 느껴진다 다음에는 일필휘지 인간인 척 그냥 하루에 정리해야지 암튼 4주 차도 성공
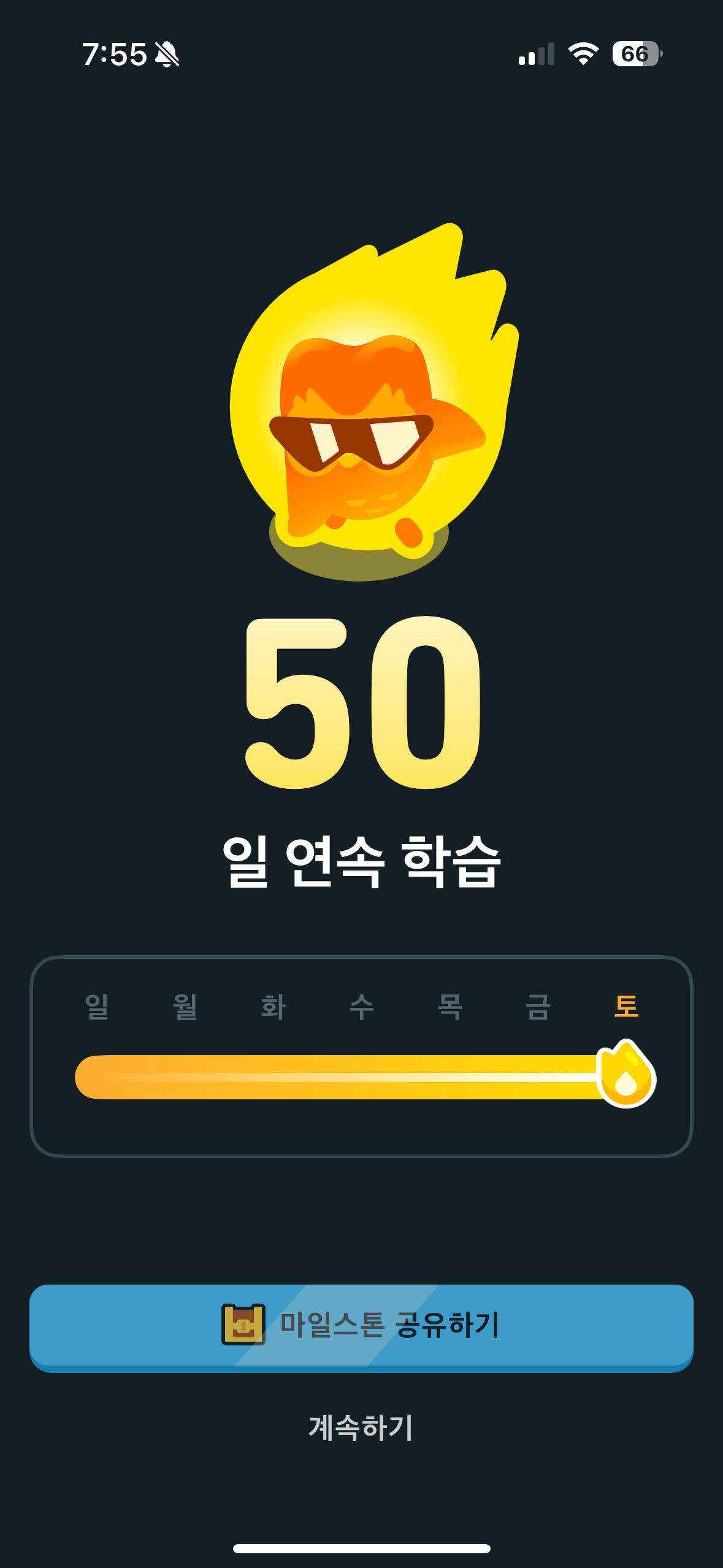
작년 말 세운 개인적인 목표가 하나 있는데 그건 언어 공부 어플 1년 동안 꾸준히 사용하기이다 그래서 가장 만만한 듀오링고를 다운로드하여 시작했는데 드디어 1차 목표(?)인 50일을 달성해 기념으로 포스팅하려 한다.
사실 저는 모두가 공인하는 귀차니즘 끝판왕이라죠 티니핑 테스트했는데 차나핑 나옴... 뭔지 몰라서 유튜브로 차나핑 소개영상 찾아봤는데 차나핑은 말끝마다 차나를 붙이고 다니면서 자기가 귀찮아서 사람들 재우고 다닌다,,,;;
암튼 듀오링고는 무료로도 사용할 수 있고 배울 수 있는 언어도 다양해서 활용도가 매우 높은 어플이다. 안 할까 봐 바탕화면에 위젯 설치해 뒀는데 부엉이 캐릭터가 은근 귀엽고 웃겨서 캡처해 뒀다 공부 안 하면 저렇게 울거나 화냄
가끔 이런 모습일 때는 당황스럽긴 하다^^ 부엉이 이름이 듀오라고 한다. Duo Owl 이라는데? 오늘 처음 아랏네
이건 30일 달성하고 신나서 캡처했다 뿌듯
광고
무료로 사용하면 한 번씩 광고가 뜨는데 어떤 날은 광고가 엄청나게 길고... 또 다른 날은 짧다 불편할 정도는 아니라 그냥 광고 보면서 쓴다죠
이렇게 영상 형태로 자기네 구독형 요금제를 광고할 때도 있고 아주 짧은 이미지 또는 영상이 들어간 광고도 있다.
요금제 가격 및 기능 비교
말나온 김에 사용 가능한 요금제를 살펴보자 듀오링고는 슈퍼 / 맥스 두 가지로 나뉘고 혼자 사용하거나 패밀리 요금제로 최대 6명이서 나눠서 사용 가능하다 개인은 월 구독이 되지만 패밀리는 연간 구독만 가능한 듯?
요금제
월 구독
연 구독
인당 금액
Super (개인)
14,000
87,000
-
Super (패밀리)
-
129,000
21,500
Max (개인)
28,000
174,000
-
Max (패밀리)
-
255,000
42,500
무료와 슈퍼, 맥스의 차이가 궁금해지는데, 슈퍼와 맥스 모두 광고 없이 무제한으로 연습할 수 있고 맥스는 AI 캐릭터 릴리와 영상 통화하는 새로운 기능이 추가되었다 나는 기초 공부만 하면 되는지라 가끔 무료 체험만 해보는 중
일반
슈퍼
맥스
학습 콘텐츠
O
O
O
무제한 하트
X (하루 5개)
무제한
무제한
광고 제거
X
O
O
스킬 연습
X
O
O
틀린 문제 복습
X
O
O
무료 도전
X (XP 소모)
O
O
영상 통화
X
X
O
수준 파악하기 : 점수와 CEFR 등급
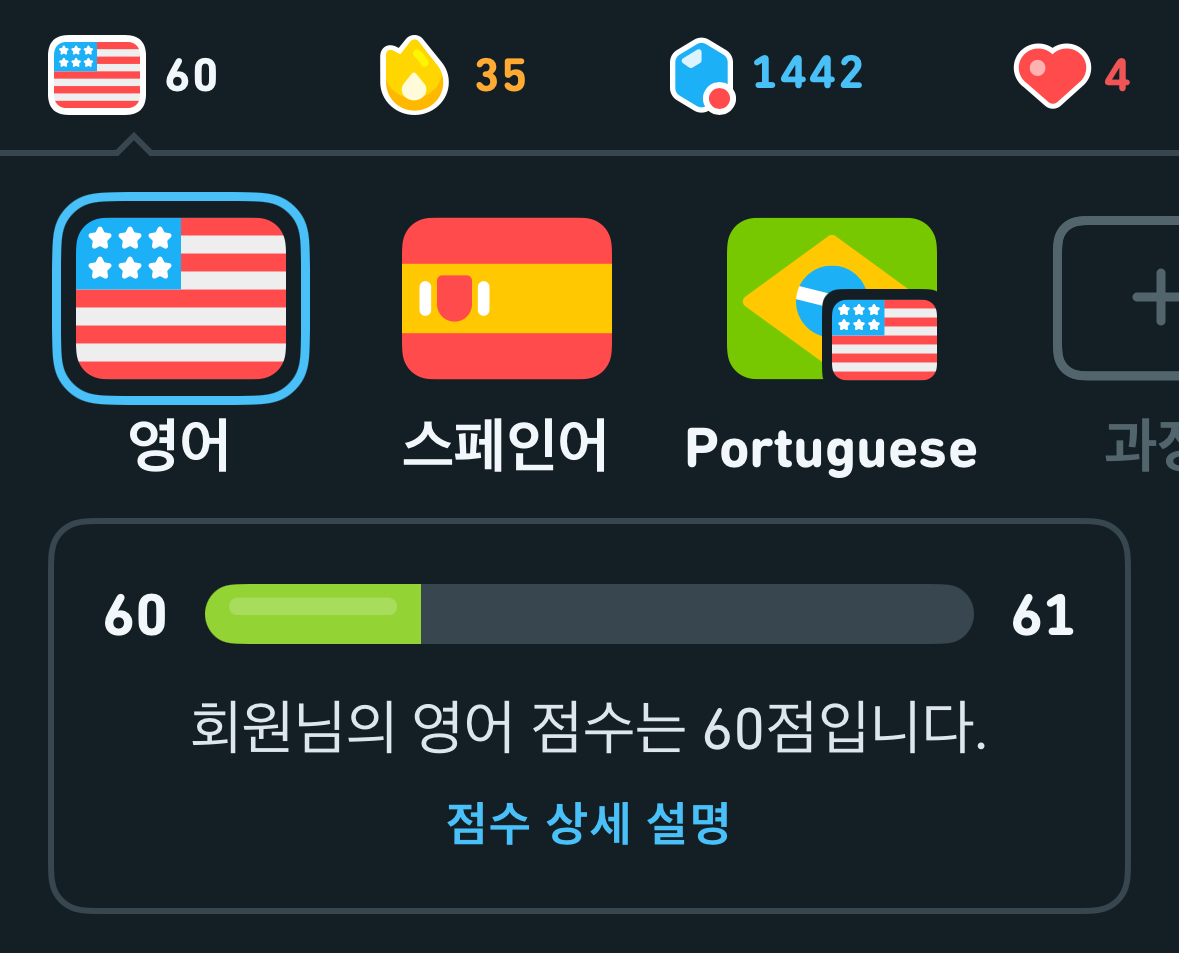
듀오링고는 한 번에 최대 4개 과정을 공부할 수 있나 보더라 나는 영어, 스페인어, 브라질식 포르투갈어를 공부하고 있다 스페인어를 중점적으로 공부하고 그다음에 시간 나면 영어를 추가적으로 하고 있다 스페인어 포인트? 경험치?인 XP만 투명하게 높은 거 보이시나요^^
듀오링고는 내 수준이 어느 정도인지를 점수와 CEFR 등급으로 알려준다. CEFR(유럽연합 공통언어 표준등급)은 언어 능력을 설명해 주는 국제 공인 표준이라고 하는데 대충 아래와 같이 6개 등급으로 나누는 것 같다. A1: 입문, A2: 초급, B1: 중급, B2: 중상급, C1: 고급, C2: 원어민 수준 이거 델레나 이런 유럽권 언어 시험에서 본 등급표 같은데? 아마 유럽연합 공통언어 표준이다 보니 동일하게 사용하는 것 같네
어플에서는 0점에서 160점 사이의 점수를 CEFR 등급에 매칭해서 표시해 준다. 내 수준을 계량화된 수치로 바로 가늠해 볼 수 있어 좋은 것 같다. 어플에서 소개하는 내용은 아래와 같다.
점수
CEFR 등급
설명
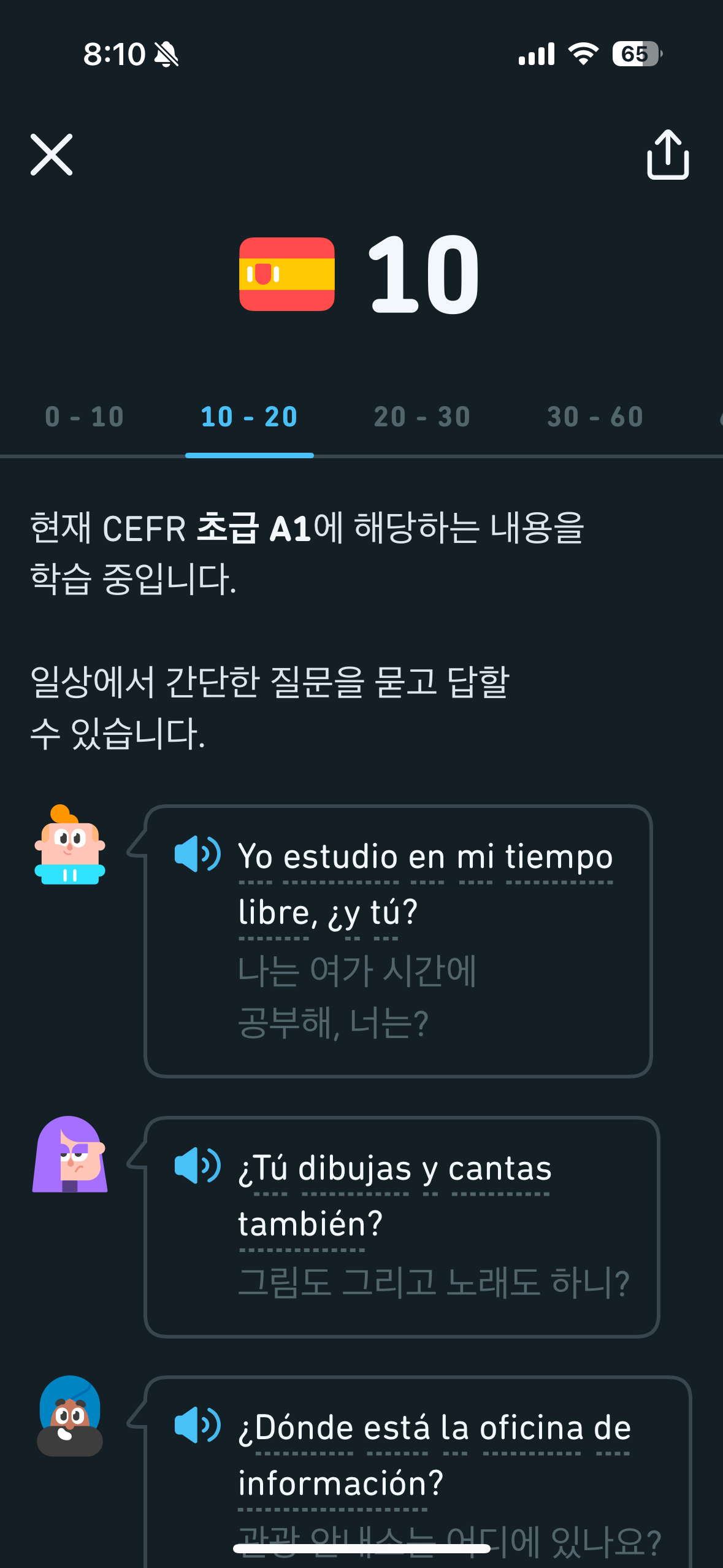
0-10
기초 A1
일상에서 필요에 따라 간단한 문구를 사용할 수 있다
10-20
초급 A1
일상에서 간단한 질문을 묻고 답할 수 있다
20-30
고급 A1
인내심을 갖고 도와주는 사람이 있으면 일상에서 약간의 대화를 할 수 있다
30-60
A2
일상적인 주제에 대해 간단한 대화를 할 수 있다
60-80
초급 B1
여행할 때 발생하는 대부분의 상황을 자신감있게 처리할 수 있다
80-100
고급 B1
일상에서 발생하는 대부분의 상황을 자신감 있게 처리하고 생각을 설명할 수 있다
100-115
초급 B2
관심 있는 주제에 대해 깊이 있는 논의를 할 수 있다
115-130
고급 B2
자신의 생각을 편안하게 표현할 수 있다. 해당 언어를 사용하여 일, 공부 등을 할 수 있다
130-160
C1~C2
일상생활에서 듣거나 읽는 내용을 모두 쉽게 이해할 수 있으며, 뉘앙스에 맞게 생각을 표현할 수 있다
암턴 [영어]부터 살펴보자면 난 60점 초급 B1에 해당한다. 본투비 코리안답게 듣는 건 진짜 잘하는데 말하는 건... 듀오링고랑 병행해서 AI 영어 회화 어플인 플랭으로도 공부하고 있는데 주어 술어 호응 안 맞기나 관사 빼먹는 건 일상이라죠 ㅋ 알고는 있지만 말로는 잘 나오지 않는 기초적인 것들부터 다시 잡아보려고 듀오링고 영어 시작한 것도 있다 열심히 해서 115-130으로 진입하는 게 목표입니다
그다음 [스페인어]도 살펴보자면 난 10점 초급 A1에 해당한다. 게으른 탓에 포스팅을 조금 늦게 했는데요 그 사이에 1점이 올라갔어요 사진 캡처가 중구난방인 점 이해점,,,
사실 나는 스페인어를 아주아주 조금 할 줄 안다 스페인 드라마나 노래를 좋아해서 대충 때려 맞추는 수준? ㅎㅎ 작년에 2달 동안 스페인 여행을 다니게 되었는데, 그전에 유튜브로 초급/중급 문장 100개 영상 급하게 돌려 보고... 그걸 기반으로 생존 스페인어로 여행다녔다^^7 하지만 동사 변화나 문법으로 넘어가면 눅우세요가 되길래 계속 공부하고 싶어서 듀오링고를 시작했다 목표는 100점 내외 만들고 델레나 플렉스 시험 보기다
포르투갈어는 거의 공부하지 않으니 스킵,,,
암턴 50일간 듀오링고를 꾸준히 사용해 보니 너무 좋다 하루에 5분 내외로 투자하면서 공부하고 오늘도 해냈다는 뿌듯함도 얻고 전반적으로 만족!
한 가지 아쉬운 점은 말하기 기능은 내가 조금 느리게 말하는 편인데 내 문장 말하기가 다 끝나기도 전에 얘가 인식을 다했다고 띠링 울리면서 넘어가려고 하는 점? 저 아직 말하는 중인데요ㅠ^ㅠ
여담인데 계속 꾸준히 성장할 회사 같아서 주식을 사보려고 했다 근데 320달러 너무 비싸요 52주 최저가 60달러였던 적도 있는 걸 보니 나만 성장성 있다고 생각한 게 아니었나 보다,,, 눙물 구독료 대신 아껴서 나중에 주식 1주 사볼까 한다 근데 얘네 배당금 주나? 요새 배당주에 맛들임
블로그 쓸 때마다 이것저것 목표를 내뱉고 있다 그건 모두 말해야 뭐라도 하기 때문... 말하면 사실될 일이라는 말도 있잖아요? 이렇게 여기저기 말하고 조금이라도 하다 보면 뭐라도 되겠지! 성공한 사람들의 특징이 한 분야를 오래 팠다는 거라잖아요?
그런 의미에서 나는 1년 꾸준히 사용하기를 내세웠는데 듀오링고 한국 공식 인스타그램은 나보다 더하길래 뽀려왔다 무려 연속 학습 50년 티셔츸ㅋㅋㅋㅋㅋㅋㅋㅋ 묘하게 탐나는데 만들어서 팔아조요
출처 : 듀오링고 한국 공식 인스타그램 게시물
마지막으로 나와 함께 50년을 함께 할 사람이 있다면,,, 내가 잘하고 있는지 감시하거나 서로 감시할 의사가 있다면,,, 팔로우해주세요 같이 해요 듀오링고